

Dedicated SQL Pools have a feature called Materialized Views which can generate a pre-calculated/processed dataset ready for consumption and is automatically updated as new data is added to its source tables. It is useful in scenarios where a dataset is required to be calculated and the processing is complex and/or has many joins. Although we don’t have the same option in Serverless SQL Pools, we can use a CETAS process (CREATE EXTERNAL TABLE AS SELECT) to generate a dataset and save that dataset to the data lake ready for querying. For example, we could pre-calculate a dataset ready for Power BI to consume, or any other process that can either connect to Serverless SQL Pools or to the Azure Data Lake. This can be useful in scenarios where we wish to pre-calculate a dataset to reduce the data processed each time this data is requested.
In part 1 we’ll create a process in which we can invoke the processing and exporting of any View created in a Serverless SQL Pools database to a new folder in the Data Lake. We will then use a View to select only the latest snapshot of the data. In this scenario the Views we would like to export are aggregate queries which are pre-calculating data to a higher level of granularity than the source data.
Part 2 we’ll discuss options when triggering the process using Pipelines.
High-Level Process
- Create 2 Views over parquet data within Azure Data Lake Gen2
- Create a View that aggregates the data from the 2 Views, this will be the dataset saved to the Data Lake
- Create a Parquet file format for use in the CETAS statement
- Deploy the stored procedure in a Serverless SQL Pools database, ensuring to change any relevant data sources
- Execute the stored procedure and pass in the View name
- Check the output and query the current snapshot data using a new auto-generated View
It’s important to note that this process only uses the external table to generate the dataset and export to the data lake, it is deleted after the dataset is generated as it is not required. A View is used to select data from the dataset.
GitHub
The Stored Procedure code is available in the serverlesssqlpooltools repo
Walkthrough
This walkthrough assumes that an existing Serverless SQL Pools database exists, data exists in an Azure Data Lake Gen2 account, and a Data Source has been created to connect Serverless SQL Pools to the Data Lake. Please see Getting Started with Azure Synapse Analytics SQL Serverless to see an example of this process.
Note that we are not implementing any form of incremental dataset processing, each time the process runs it will aggregate over the entire source dataset. Please bear this in mind in terms of data processed.
Create Views
In this section we’ll create 3 Views, 2 Views to connect to the Data Lake, and 1 View to aggregate the data.
Create Views over Source Data
These 2 Views connect to an Azure Data Lake Gen2 account and selects Parquet file data from a folder location. Please note that although the data is location in a Year/Month/Date folder structure, we are not exposing this using the filepath function (keep the View simple for this exercise).
--create a view to select the web telemetry data
CREATE VIEW LDW.vwFactWebTelemetry
AS
SELECT
UserID,
EventType,
CAST(EventDateTime AS DATE) AS EventDate,
ProductID,
URL AS SessionURL,
Device,
SessionViewSeconds,
1 AS EventCount
FROM
OPENROWSET
(
BULK 'webvisitmessagescleansed/*/*/*/*.parquet',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Parquet'
)
WITH
(
UserID INT,
EventType VARCHAR(20),
EventDateTime DATE,
ProductID SMALLINT,
URL VARCHAR(50),
Device VARCHAR(10),
SessionViewSeconds INT
) AS fct
--create a view for a date dimension
CREATE VIEW LDW.DimDate
AS
SELECT *
FROM OPENROWSET
(
BULK 'conformed/dimensions/dimdate/*.parquet',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Parquet'
) as fctCreate View to Aggregate Data
This View is used to aggregate the row-level view and is the dataset that will be exported to the data lake.
CREATE VIEW LDW.vwFactWebTelemetryAggregate
AS
SELECT
FT.EventDate,
D.WeekDayName,
D.MonthName,
FT.EventType,
FT.Device,
SUM(FT.EventCount) AS EventCount,
SUM(FT.SessionViewSeconds) AS SessionViewSeconds
FROM LDW.vwFactWebTelemetry FT
LEFT JOIN LDW.DimDate D ON D.Date = FT.EventDate
GROUP BY
FT.EventDate,
D.WeekDayName,
D.MonthName,
FT.EventType,
FT.DeviceCreate Parquet File Format
The SQL below will create a Parquet file format which is used in the CETAS statement.
CREATE EXTERNAL FILE FORMAT SynapseParquetFormat
WITH (
FORMAT_TYPE = PARQUET
);Now that we have created the Views and Parquet File formats deployed, we’ll now deploy the stored procedure which will select data from the required View and load to a new datetime stamped folder in the Data Lake.
Create Stored Procedure for Processing Views
Within the same Serverless SQL Pools database that the above Views and Parquet file format exist, run this CREATE PROC statement to create the stored procedure.
The stored procedure logic is as follows:
- Drops external table if it exists (this does not drop any data in the Data Lake)
- Generates the CETAS statement and exports the View passed in via the parameter to the specified location appended with a datetime stamp.
- Generates a View which is used to select data from the latest folder
CREATE PROCEDURE LDW.GeneratePreComputedDatasets
@SourceView NVARCHAR(200),
@Location NVARCHAR(1000),
@DataSource NVARCHAR(100),
@FileFormat NVARCHAR(100)
AS
BEGIN
--declare variables, set the process date for the folder name, and set the locations
DECLARE @LocationFull NVARCHAR(1100),
@LocationTopLevel NVARCHAR(1100),
@ProcessDate NCHAR(16),
@SQLDrop NVARCHAR(2000),
@CreateExternalTableString NVARCHAR(2000),
@CreateCurrentAggregateView NVARCHAR(2000)
SET @ProcessDate = FORMAT(GETDATE(),'yyyyMMddHHmmss')
SET @LocationFull = CONCAT(@Location,REPLACE(@SourceView,'.',''),'/',@ProcessDate)
SET @LocationTopLevel = CONCAT(@Location,REPLACE(@SourceView,'.',''))
--Check for existence of an external table and drop if found
SET @SQLDrop = 'IF OBJECT_ID(''' + REPLACE(@SourceView,'.vw','') + '_PreComputeTable'') IS NOT NULL BEGIN DROP EXTERNAL TABLE ' + REPLACE(@SourceView,'.vw','') + '_PreComputeTable END'
EXEC sp_executesql @SQLDrop
--generate the SQL script to create the external table and export the View data
SET @CreateExternalTableString =
'CREATE EXTERNAL TABLE ' + REPLACE(@SourceView,'.vw','') + '_PreComputeTable
WITH
(
LOCATION = ''' + @LocationFull + ''',
DATA_SOURCE = ' + @DataSource + ',
FILE_FORMAT = ' + @FileFormat + '
)
AS
SELECT
*
FROM ' + @SourceView
EXEC sp_executesql @CreateExternalTableString
--drop the external table as we do not need it, it is only being used to generate the data. We'll use a View to select the data
SET @SQLDrop =
'IF OBJECT_ID(''' + REPLACE(@SourceView,'.vw','') + '_PreComputeTable'') IS NOT NULL BEGIN DROP EXTERNAL TABLE ' + REPLACE(@SourceView,'.vw','') + '_PreComputeTable END'
EXEC sp_executesql @SQLDrop
--drop the existing precompute View, we will re-create it
SET @SQLDrop =
'IF OBJECT_ID(''' + @SourceView + '_PreComputeCurrent'') IS NOT NULL BEGIN DROP VIEW ' + @SourceView + '_PreComputeCurrent END'
EXEC sp_executesql @SQLDrop
--create a view to show the current data
SET @CreateCurrentAggregateView =
'CREATE VIEW ' + @SourceView + '_PreComputeCurrent
AS
WITH CurrentFolder
AS
(
SELECT MAX(fct.filepath(1)) AS CurrentAggregates
FROM
OPENROWSET
(
BULK ''' + @LocationTopLevel + '/*/*.parquet'',
DATA_SOURCE = ''' + @DataSource + ''',
FORMAT = ''Parquet''
) AS fct
)
SELECT fct.filepath(1) AS CurrentAggregateFolder,
*
FROM
OPENROWSET
(
BULK ''' + @LocationTopLevel + '/*/*.parquet'',
DATA_SOURCE = ''' + @DataSource + ''',
FORMAT = ''Parquet''
) AS fct
WHERE fct.filepath(1) IN (SELECT CurrentAggregates FROM CurrentFolder)'
EXEC sp_executesql @CreateCurrentAggregateView
END;Execute the Stored Procedure
We can now run the stored procedure and observe the outputs. Note than we can pass in any View name to create a dataset.
EXEC LDW.GeneratePreComputedDatasets
@SourceView = 'LDW.vwFactWebTelemetryAggregate',
@Location = 'precomputeddatasets/aggregates/',
@DataSource = 'ExternalDataSourceDataLakeMI',
@FileFormat = 'SynapseParquetFormat'Results
We can see that the process has output data to a datetime stamped folder in the desired location. In this example, the process ran 3 times therefore there are 3 folders in the data lake.


In the Serverless SQL Pools database, we can see a View has been created with the same name as the source view, with “_PreComputeCurrent” appended to the end.
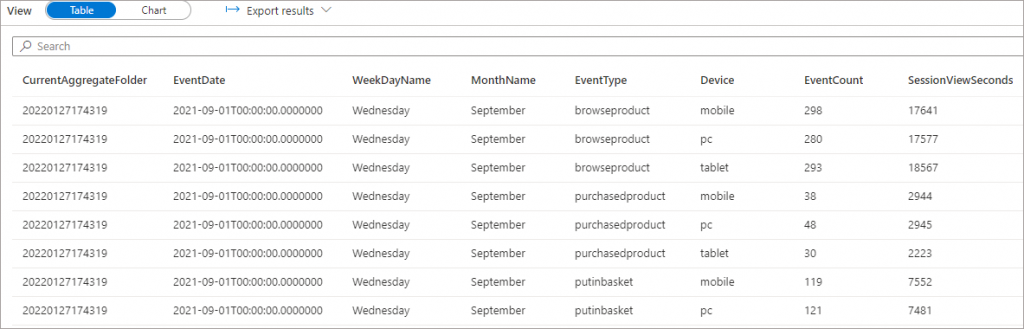
If we query this View, only the latest folder data will be returned.
Conclusion
In part 1 we have looked at how to create a process which can pre-aggregate data and export to a folder in the data lake, ready for consumption by a data application. In part 2 we will look at options for triggering this process.
 Andy
Andy