

In part one we looked at a process in which a pre-aggregated dataset can be created by Azure Synapse Analytics Serverless SQL Pools and saved to an Azure Data Lake Gen2 folder. This data can then be queried either using Serverless SQL Pools or read from the Data Lake by an application such as Power BI. The reason why we may wish to do this is to pre-calculate a dataset and have that resulting dataset ready to be queried (similar to a Materialized View in Dedicated SQL Pools). The process can be triggered at any point and the data will be written out to the Data Lake into a new folder.
This part now looks at the options for triggering this process. Part 1 showed a simple triggering process which is to invoke the stored procedure manually. We’ll now look at several options to trigger this process.
GitHub
The SQL code outlined in part 1 is available on GitHub here.
Blog Outline
- Manually Trigger Stored Procedure
- Creating the pipeline to execute the data load process
- Use a Scheduled trigger to execute the pipeline
- Trigger pipeline when new data becomes available
Manually trigger stored procedure
This is the simplest method and all that’s required is to execute the stored procedure from a SQL client including Synapse Studio, SQL Server Management Studio (SSMS), and Azure Data Studio.
--trigger stored procedure
EXEC LDW.GeneratePreComputedDatasets
@SourceView = 'LDW.vwFactWebTelemetryAggregate',
@Location = 'precomputeddatasets/aggregates/',
@DataSource = 'ExternalDataSourceDataLakeMI',
@FileFormat = 'SynapseParquetFormat'This works fine if we’re simply looking at manually triggering the process on an ad-hoc basis. What about scenarios where we wish to run the process on a schedule or when new data arrives? We can use Pipelines in Synapse Analytics for this. Please note there is a cost to using Pipelines, this is outlined in the Synapse pricing document. As the techniques below are only related to Orchestration Activity Run activities, the cost is (for GBP currency) £0.747 per 1,000 runs.
Creating the Pipeline to execute the data load process
Let’s build the Pipeline which will trigger the stored procedure. We’ll keep it simple here but still offer flexibility for iterating over a series of Views we wish to output to the Data Lake. For this we’ll use a For Each process to loop through the Views and execute the stored procedure stored in the Serverless SQL Pools database.
Creating a Linked Service to Serverless SQL Pools Database
We’ll create a Linked Service to the specific Serverless SQL Pools database that the stored procedure was created in. Please note we are entering the connection information (Key Vault can be used) to specify the Serverless SQL endpoint, this can be obtained from the Azure Synapse Analytics workspace overview in the Azure portal.
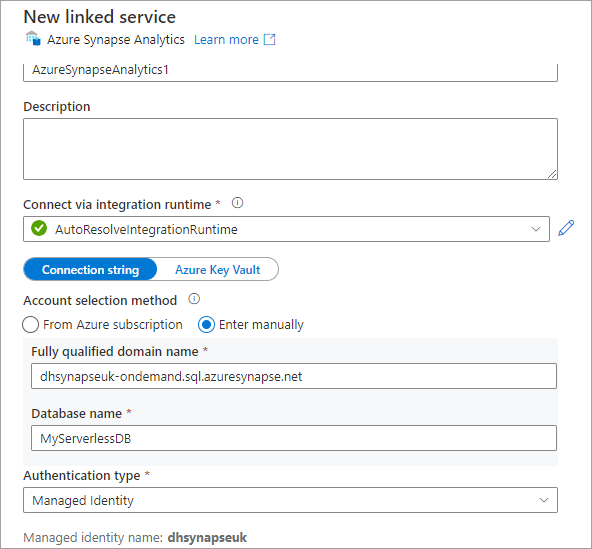
After creating the linked service we can use a Lookup activity to get a list of Views from the Serverless SQL Pools database. The SQL query in this scenario looks for any View names with “Aggregate” in the name, this of course can be changed to meet any requirements to obtain the list of View names to export.
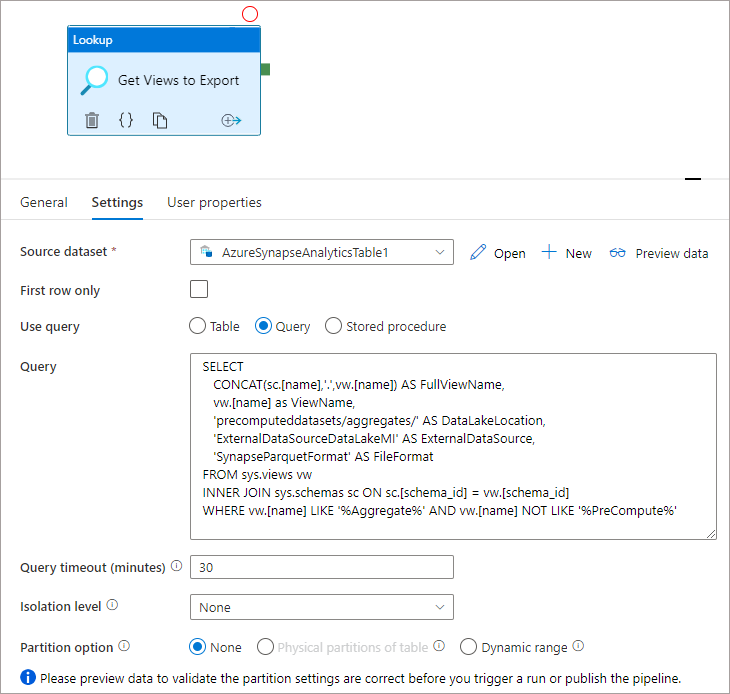
The result of the above query in this example will return 2 Views, these are the Views we wish to export to the Data Lake.

We’ll now add a For Each activity which will take the output from the Lookup activity and iterate over each row.
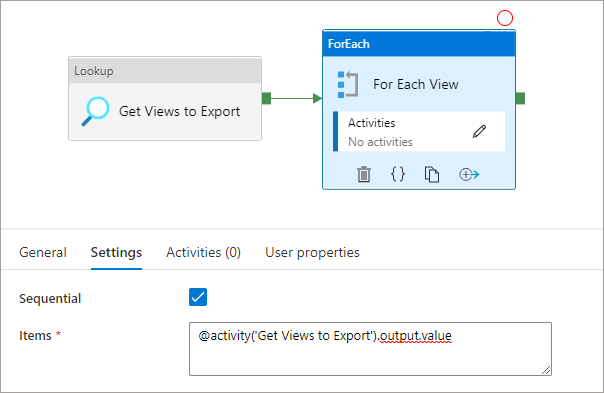
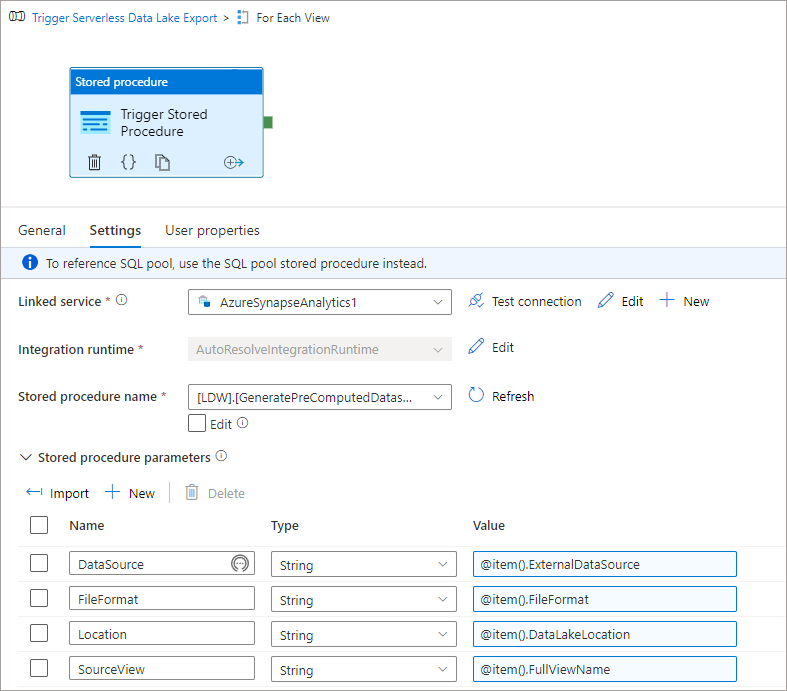
- Configure the Linked Service to use the Serverless SQL Pools connection created earlier.
- We’ll select the Stored procedure name as the loading procedure (created in part 1).
- We’ll then click Import under the Stored procedure parameters section to bring in the parameters.
- We can then add the ForEach loop items into the Value fields for each parameter.
Once completed, we can trigger the process manually by clicking the Debug button in the menu bar. If the above has been configured correctly then the output of the job should show as follows:
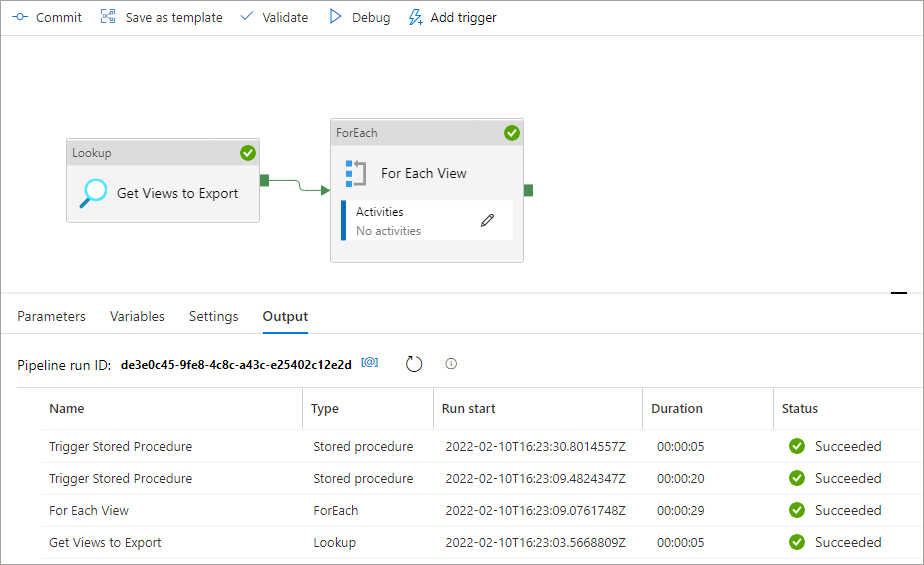
If we look at the Data Lake folders, we can see that new folders have been created with Parquet files containing the exported aggregated data.


Now that we have built the Pipeline which executes the process, let’s now look at options to trigger the Pipeline.
Use a Scheduled Trigger to execute the Pipeline
We’ll now create a trigger which will be scheduled to execute once a day at 6AM. Within the Pipeline, click the Add Trigger in the top menu and select New/Edit.
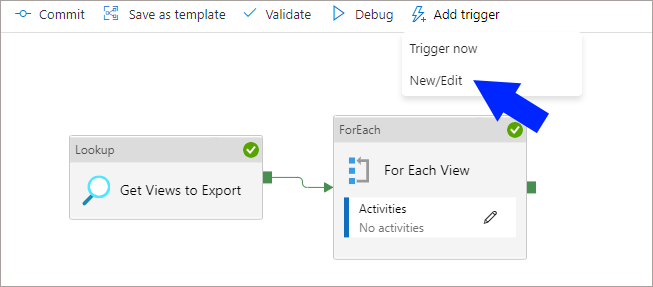
In the right-hand menu that appears, select Choose Trigger > New. You can now enter the relevant information as shown in the following list and image.
- Name: Trigger Daily
- Type: Schedule
- Start date: enter the date and time you wish the trigger to start from
- Time Zone: enter the appropriate time zone
- Recurrence: select when the event with repeatedly trigger
- Execute at these times: enter the hours and minutes you would like the repeated schedule to execute. E.G 6 and 0 for 6AM.
- Start trigger on creation: enable ensure the trigger runs successfully.
Once the relevant information is entered, click Commit then Publish. The trigger must be published to become active.
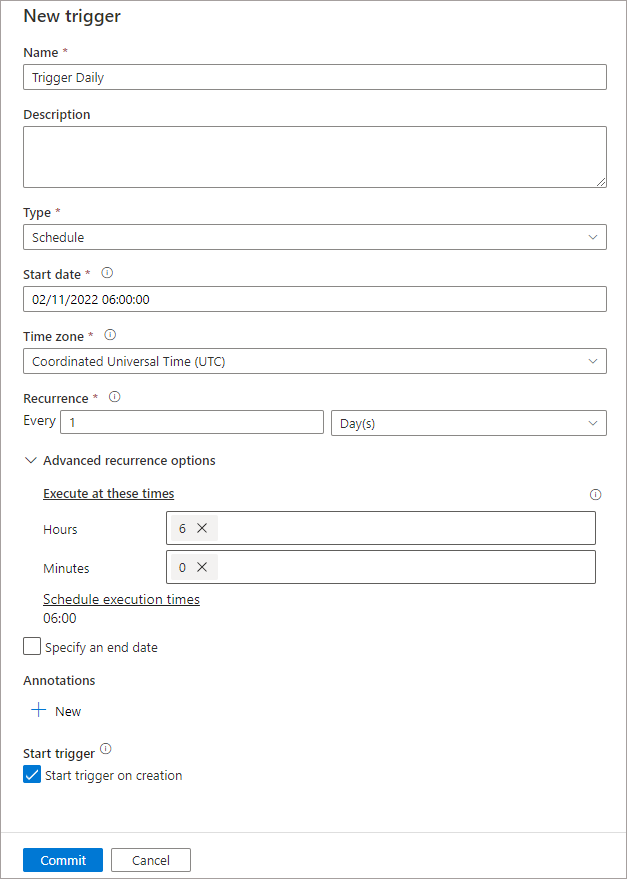
The trigger is now active and will execute the pipeline at 6AM each day, this will trigger the stored procedure and generate the aggregate datasets from the Serverless SQL Pools Views.
Trigger Pipeline automatically when new data is available
We have another option when creating a schedule to proactively respond to a storage event when it happens. In this scenario we can create a trigger to execute the pipeline when new data arrives. This is useful to react as soon as data is available and can mitigate any scenarios where data arrives late and a schedule misses the new data.
Please note that you must ensure you have calculated the data processed cost each time the dataset is generated, if data arrives frequently and you wish to have the aggregated data available immediately this may increase data processed costs.
Prerequisites
- Ensure the storage account is configured as an Azure Data Lake Storage Gen2 or General-purpose version 2 storage account.
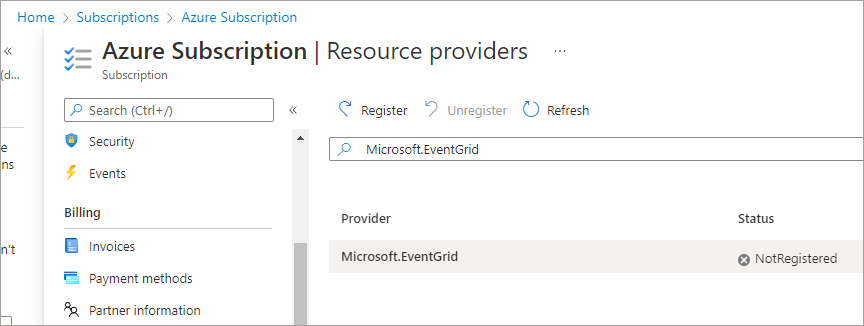
- You must ensure that the Microsoft.EventGrid resource provider is registered in the subscription your resources are in. To do this, browse to the Azure Subscription area in the Azure Portal, click Resource Providers under the Settings area. Search for “Microsoft.EventGrid” and click Register.
- Ensure that the user or the Synapse Managed Identity accessing the Data Lake storage account from the Synapse analytics workspace has at least Contributor access to the storage account. Further details for authentication can be found here.
Create Trigger
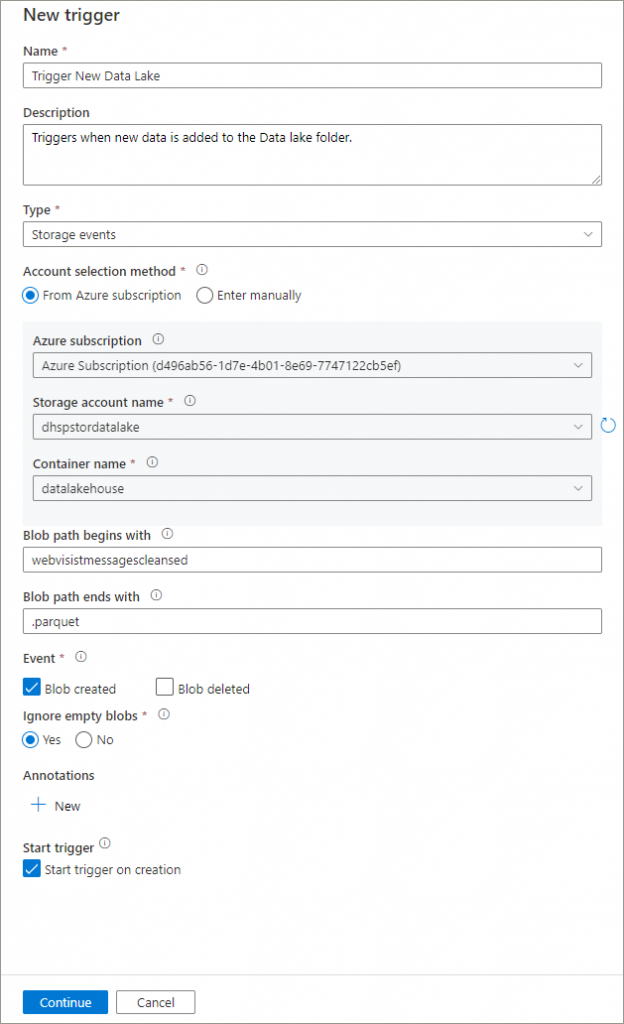
We can now follow the same process as before, but we will now select storage events in the Type field.
- Name: Trigger New Data Lake
- Type: Storage events
- Account selection method: Select the appropriate storage account and enter the top-level container name
- Blob path begins with: enter the folder within the container you wish to be included in the trigger. In this scenario we have entered the root folder that the data is saved to. The data is saved to a \YYYY\MM\YYYY-MM-DD folder structure so any new data added for any year, month, or date will cause the trigger to process.
- Blob path ends with: As the new data is saved as Parquet data, we enter limit triggering to occur when .parquet files are uploaded.
- Start trigger on creation: enable ensure the trigger runs successfully.
Once the relevant information is entered, click Commit then Publish. The trigger must be published to become active.
Any errors with the trigger will be shown when publishing the trigger, likely errors include the EventGrid resource provider not being registered, and account permissions on the storage account.
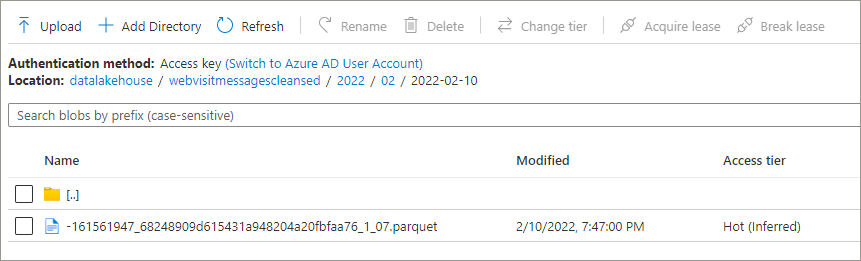
Test Trigger by uploading new Parquet data
Once the trigger is active, we can now test by uploading a new file to a new folder. The trigger will fire if any process is used to move/create a parquet file in the folder structure.
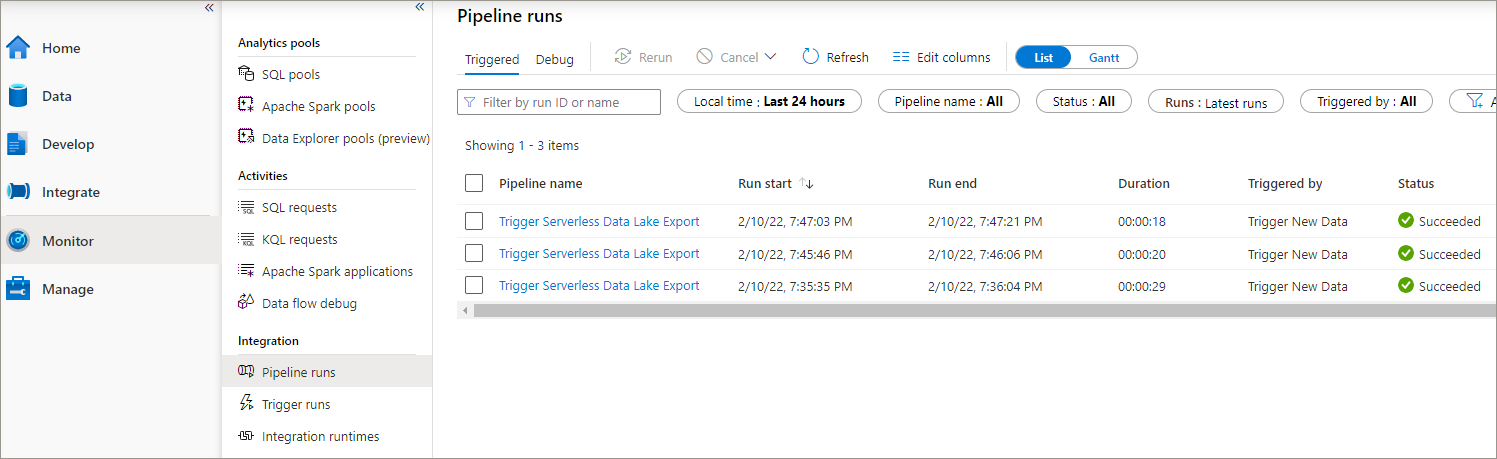
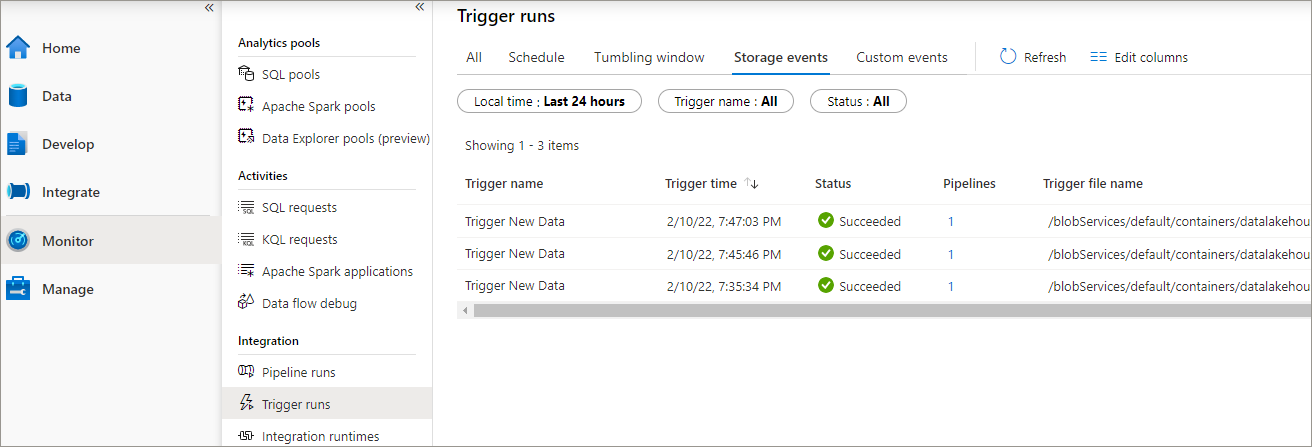
In the Monitor area within Synapse Studio, we can look at both the Trigger runs and Pipeline runs areas to confirm that the trigger has fired and triggered the pipeline. In the example below, the trigger has executed 3 times.
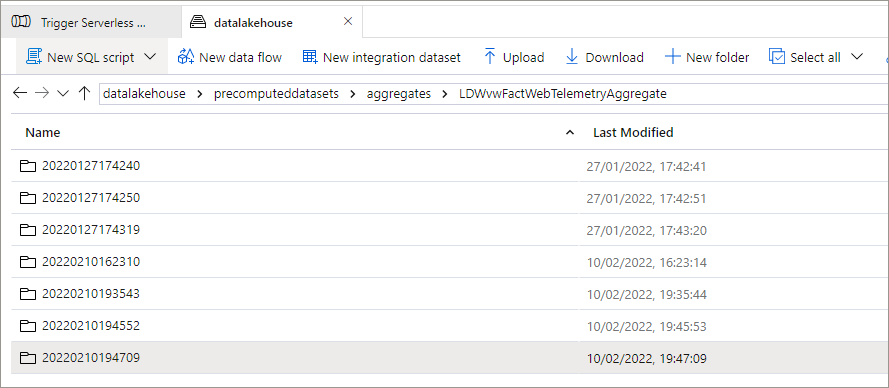
In the aggregates folder in the Data Lake, we can see 3 folders have been created as the new data arriving in the source data lake folders has triggered the aggregate exporting process.
Custom Events and External Services
We can also use Custom Events within a Pipeline trigger which can use Azure Event Grid. We may look at this option in a future blog post. There is also the option to use external services to either call the Pipeline activity which triggers the Stored Procedure or the stored procedure directly itself. This can include Power Automate and Azure Functions.
Conclusion
In this part of the 2 part series, we have created scheduled and event-based triggers to execute the Serverless SQL Pools aggregate creation process. We are therefore able to set our data loading process to meet business requirements depending on how frequent the data needs to be up-to-date.
References
 Andy
Andy