

Fabric Warehouses are a SQL focused service for building data warehouse structures within a Fabric (Power BI) workspace. The storage of Warehouses is based on the Delta Lake format utilizing Parquet file as the storage layer.
There’s a feature within Warehouses called Cloning. This allows you to make a copy of a table. However, we’re not copying the data, just the table metadata (schema, transaction log) – this is called Zero Copy cloning. This is actually based on the OSS (open source) Delta Lake shallow clone feature. What’s worth noting is Databricks has additional cloning functionality in the form of full copies where the data is copied along with the table metadata.
We can use cloning for a variety of reasons such as testing new data changes, snapshotting tables at a particular point in time, taking backups of table.
So how do we clone a table? What’s the syntax? It’s very simple, we just create a table and use the AS CLONE OF statement. Note that we can create a clone in another schema (but not another Warehouse).
--create table clone CREATE TABLE <schema>.<new_table_name> AS CLONE OF <schema>.<existing_table_name>
Walkthough
Let’s go through an example below, we have just one table, DimEvent, which we’ll load with data and then clone. You can create a new Warehouse in Fabric just for this walkthough, or use an existing Warehouse. We’ll use the Fabric GUI for running the SQL, so create a new SQL Query and paste in the code below to create a new table and insert 3 rows of data.
CREATE TABLE [dbo].[DimEvent]
(
EventTypeKey SMALLINT NOT NULL,
EventType VARCHAR(20)
);
--insert static data
INSERT INTO dbo.DimEvent
(EventTypeKey,
EventType)
VALUES
(1,'putinbasket'),
(2,'browseproduct'),
(3,'purchasedproduct');
Once that’s done, we can run the clone command to create a copy of the table called DimEvent_Development:
CREATE TABLE dbo.DimEvent_Development AS CLONE OF dbo.DimEvent;
If we run a SELECT on both tables, we’ll see the same results:

Now let’s look at the underlying storage. I connected to the Warehouse storage using Azure Storage Explorer (details here) as OneLake uses the Azure Data Lake Gen2 storage APIs. My URL to connect was: https://onelake.dfs.fabric.microsoft.com/Data Relay 2023/DR2023_Warehouse.Warehouse/
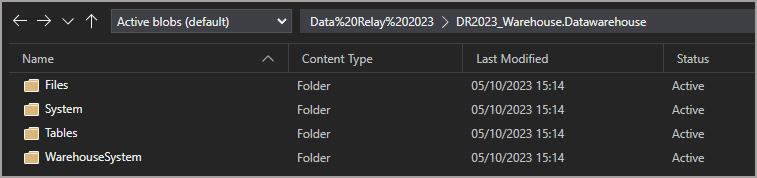
Here’s the root folder of the Warehouse, note the Files, Tables, and WarehouseSystem folders as we’ll be referring to these later.
It’s worth noting I cannot rename or delete any of these folders or files, and that’s a really really good thing!
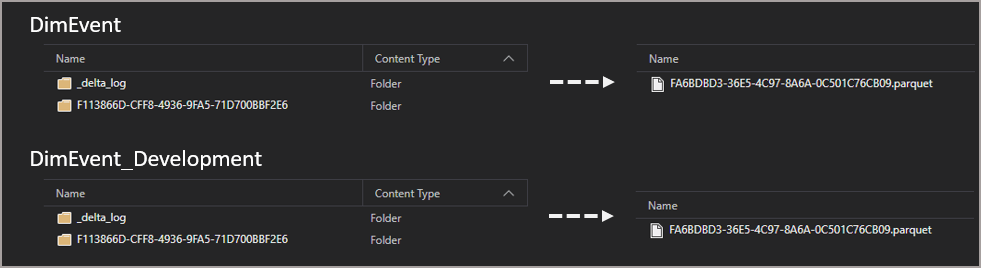
Browse the Tables folder and we’ll see the original table and the cloned table have separate folders.

In the image below we can see that although the documentation states this is a “zero-copy” clone, we can actually see a folder with a parquet file in. What’s interesting is that it’s the same parquet file from the base table.
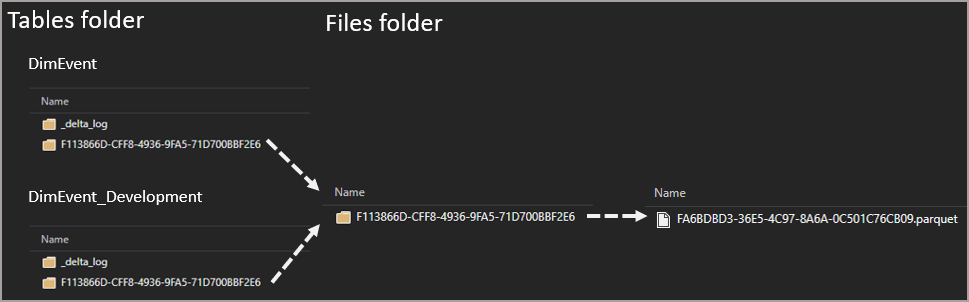
At this point, it’s worth noting what’s happening with the storage view here. What we’re seeing in the Tables folder in the storage is actually a pointer to the Files folder. This is for all tables whether cloned or not. It’s just metadata really, each Table folder is pointing towards 1 or more File folders.
Now let’s modify the cloned table and see what happens to the storage. Bear with me in the next section! 🙂
Data Modification
Let’s run a SQL update to change all the rows in the cloned table.
UPDATE dbo.DimEvent_Development SET EventType = 'Some Other Value';
This time we get a new folder in the Files folder and within that, we get a new Parquet file as this is an UPDATE (INSERTS also get new files, DELETES will just get a transaction log modification – read up on deletion vectors if interested). We may not get a new folder if the data changes happen close together (I believe new folders are created after a period of time).
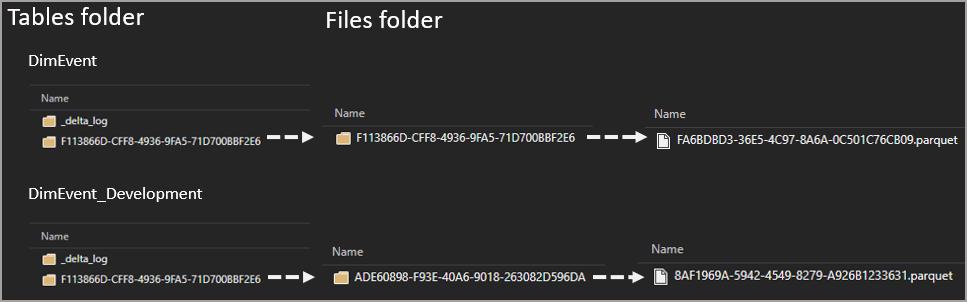
However you may notice that the folder name in the Tables folder for the cloned table still shows as the old folder name. This is where things get interesting…when any table is first created a folder will appear in the Tables section for that table with a _delta_log folder containing a transaction log. When that table gets loaded for the first time, a folder will appear in the Files folder containing the parquet files, this will then appear in the Tables folder for that table (a pointer).
When subsequent changes are made to the table, new folders can be written to the Files folder with new Parquet files, but the original folder in Tables will not change. We also don’t see any new transaction log files in the Tables _delta_log folder. The subsequent transaction log files appear in other folders under the WarehouseSystem folder.

If we browse through this folder (down through Internal > MF) we’ll see a list of folders, each folder relates to each table. Within each folder we have the transaction files, and this is where we’ll see new transaction log files appear when we modify a table.

If I open the latest transaction log file we can see that the new folder and parquet file locations have been added with the changed data (UPDATE statement), and the old folder and parquet file have been removed.
{"txn":{"appId":"424c3456-c3dc-e5f8-530f-135019cd5974","version":1182}}
{"protocol":{"minReaderVersion":3,"minWriterVersion":7,"readerFeatures":["deletionVectors"],"writerFeatures":["deletionVectors"]}}
{"add":{"path":"ADE60898-F93E-40A6-9018-263082D596DA/8AF1969A-5942-4549-8279-A926B1233631.parquet","partitionValues":{},"size":932,"modificationTime":0,"dataChange":true,"stats":"{\"numRecords\":3}","tags":{"cell":"260"}}}
{"remove":{"path":"F113866D-CFF8-4936-9FA5-71D700BBF2E6/FA6BDBD3-36E5-4C97-8A6A-0C501C76CB09.parquet","dataChange":true,"extendedFileMetadata":true,"partitionValues":{},"size":781,"tags":{"cell":"5"}}}
As you can see, quite a bit of magic going on under the hood in the storage area.
Conclusion
So cloning tables are a very quick method of snapshotting a table for different purposes like point-in-time snapshots, backup and recovery purposes, and testing changes before making them in base tables. And it’s very interesting what’s happening in the storage layer too. Feel free to reach out to chat about this feature.
Thanks to Mark Pryce-Maher for some pointers (see what I did there…)
References
- Clone table – Microsoft Fabric | Microsoft Learn
- Clone table using T-SQL – Microsoft Fabric | Microsoft Learn
- CREATE TABLE AS CLONE OF – SQL Server | Microsoft Learn
- Integrate OneLake with Azure Storage Explorer – Microsoft Fabric | Microsoft Learn
- Table utility commands — Delta Lake Documentation
 Andy
Andy