

I trust everyone has been having fun with Fabric over the last few weeks, diving into various workload types like data engineering, data warehousing, data science, real-time streaming, all that good stuff. Well, I’m about to spoil the fun and talk about…transactions and isolation levels in Fabric SQL! I know, I know…it doesn’t exactly sound like the most interesting area but trust me, it’s important to have a grasp of what’s going on.
Transactions and ACID Principles
What do we mean by transactions? A transaction can be a single SQL statement or multiple statements that are performing actions, actions can include reading or writing data. We can initiate a transaction by starting a sequence of SQL statements with BEGIN TRANSACTION, and then using COMMIT TRANSACTION after the final statement we want included (we can also run ROLLBACK TRANSACTION at any point). The behaviour we’re looking for is that all the SQL statements in the transaction either complete successfully or are rolled back.
The use of transactions and isolation levels help a database system adhere to the principles of ACID. ACID dates back decades and it’s nothing new, it comprises of the following:
- Atomiticy: All of the statements in a transaction must either all commit or be rolled back
- Consistency: The database must be left in a consistent state after the transaction has completed
- Isolation: Ensures transactions are separated from each other
- Durable: Data is never lost or corrupted once committed
In a future blog in the Fabric SQL series I’ll dive into rollbacks and the actual parquet files themselves that are written during transactions. You can review the official documentation here from Microsoft.
Snapshot Isolation
There is currently only 1 isolation level supported in Fabric Warehouses…yes, just 1. Snapshot isolation is the only supported level (at the moment), I’ll stop a minute and let the SQL database developers and DBAs out there take a sharp intake of breath… Snapshot is called optimistic because it allows multiple transactions to do their work on the same data without much blocking. Reads can happen without blocking data modifications, and data modifications can happen without blocking reads. If I had to pick a favourite isolation level, it would be snapshot (can you have a favourite isolation level?!).
A basic comparison between SQL Server and Fabric Warehouse snapshot isolation is that multiple transactions can modify data in a SQL Server table as long as no transactions are trying to update the same row at the same time, while in Fabric this isn’t possible – multiple transactions cannot modify any rows in the same table even if they are not the same row. We’ll see this behaviour in the demo below.
Lakehouses and Warehouses storage method is Delta which supports optimistic concurrency, have a read here for more info.
Warehouse and Lakehouse Isolation Levels
Although we’ll be concentrating on using the Warehouse in this blog, it’s also worth noting that the Lakehouse SQL Endpoint also supports snapshot isolation when reading data. The Selecting Data section will work the same way in the SQL Endpoint if a transaction is started, SELECTs on tables are initiated, then data modifications are started outside of the transaction (in Notebooks, Pipelines etc).
Demo
The SQL script below creates 2 tables and inserts a few rows of data into each, note that singleton inserts is an anti-pattern on Fabric Warehouse but for demo purposes let’s ignore this 🙂 It’s a simple Products dimension table and associated Sales fact table.
--drop, create and populate tables
CREATE SCHEMA DW AUTHORIZATION dbo;
DROP TABLE IF EXISTS DW.DimProducts;
DROP TABLE IF EXISTS DW.FactSales;
CREATE TABLE DW.DimProducts
(
ProductKey INT,
ProductID VARCHAR(10),
ProductName VARCHAR(50)
);
CREATE TABLE DW.FactSales
(
ProductKey INT,
PurchaseCount INT,
PurchasePrice DECIMAL(6,2)
);
INSERT INTO DW.DimProducts
VALUES
(1,'D0268','iPhone 14'),
(2,'HY54678','Cuddly Toy'),
(3,'PO9734','LEGO Castle');
INSERT INTO DW.FactSales
VALUES
(1,1,12.99),
(1,2,25.98),
(1,1,12.99),
(2,1,5.99),
(2,3,17.97),
(2,1,5.99),
(3,1,59.99),
(3,1,59.99);
Once the tables have been created and data has been inserted, run a SELECT to preview the data from both tables.
SELECT
DP.ProductName,
SUM(FS.PurchaseCount) AS TotalPurchaseCount,
SUM(FS.PurchasePrice) AS TotalPurchasePrice
FROM DW.FactSales FS
INNER JOIN DW.DimProducts DP ON DP.ProductKey = FS.ProductKey
GROUP BY DP.ProductName
Selecting Data
In terms of using snapshot isolation level when reading data, if we want to read from several tables and have the data returned at a consistent point in time then this will help us do that. By initiating a transaction and reading data, the data will be returned from the tables at the point in time the transaction was initiated. Data modifications can happen on the tables during the read transaction and won’t affect the outcome.
From the MS documenation “Transactions can also be used for sequential SELECT statements to ensure the tables involved all have data from the same point in time.”
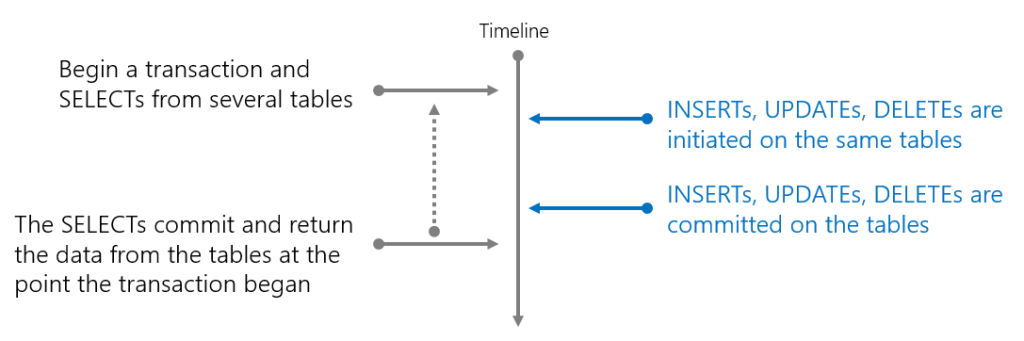
The SQL query below will query the DimProduct and FactSales tables in 2 separate queries, but they will be wrapped in a BEGIN/COMMIT TRANSACTION statement. There is a WAITFOR DELAY statement in between the 2 SQL statements to allow time to run an UPDATE on the Fact table (script is below). The expected outcome is that both SELECT statements return the same data even though an UPDATE on the Fact was started and successfully committed during the open read transaction.
--read the same tables twice
BEGIN TRANSACTION
SELECT
DP.ProductName,
SUM(FS.PurchaseCount) AS TotalPurchaseCount,
SUM(FS.PurchasePrice) AS TotalPurchasePrice
FROM DW.FactSales FS
INNER JOIN DW.DimProducts DP ON DP.ProductKey = FS.ProductKey
GROUP BY
DP.ProductName;
--keep transaction open while the UPDATE statement is run
WAITFOR DELAY '00:00:30';
SELECT
DP.ProductName,
SUM(FS.PurchaseCount) AS TotalPurchaseCount,
SUM(FS.PurchasePrice) AS TotalPurchasePrice
FROM DW.FactSales FS
INNER JOIN DW.DimProducts DP ON DP.ProductKey = FS.ProductKey
GROUP BY
DP.ProductName;
COMMIT TRANSACTION;
While the statement is running above, run the UPDATE below in another query window.
--run this a few seconds after the statement above in a new window UPDATE DW.FactSales SET PurchasePrice = PurchaseCount * 599.99 WHERE ProductKey = 1;
Both SELECTs will return the data at the point in time the transaction was initiated, while the UPDATE statement will complete successfully.
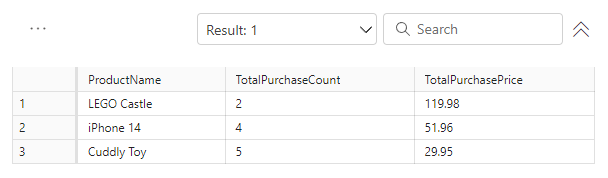
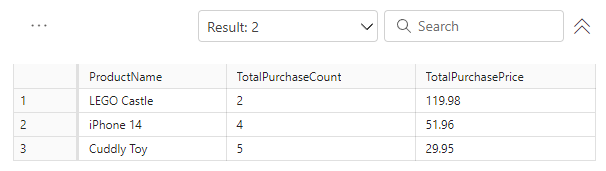
Running a SELECT again will return the new TotalPurchasePrice from the UPDATE statement.
Updating Data
What about UPDATEing data? Put simply, if there are multiple open transactions on a single table at the same time, the transaction that commits first wins, the other transactions will rollback and return an error. Yup, it’s not the transaction that started first…which means if you have an UPDATE query that is long running and another UPDATE begins and commits before the long running query, then sorry but your long running UPDATE will fail.
From the MS Docs “Conflicts from two or more concurrent transactions that update one or more rows in a table are evaluated at the end of the transaction. The first transaction to commit completes successfully and the other transactions are rolled back with an error returned.“
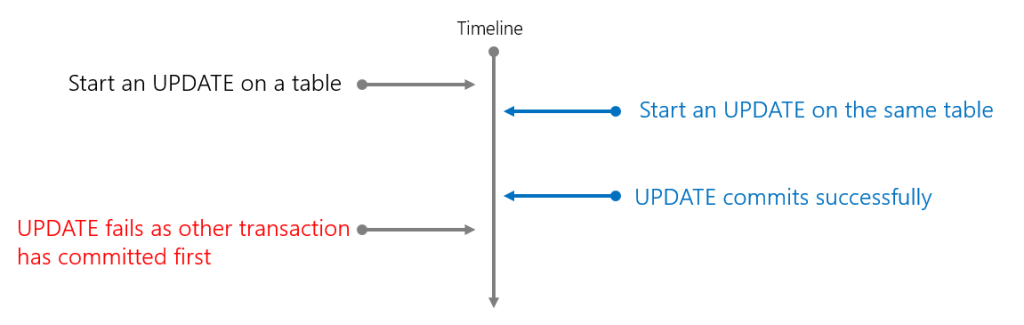
In the SQL below, we’ll start an UPDATE transaction and while it’s running, we’ll run another UPDATE on the same table. As the locks happen at the table level it doesn’t matter if we try and update the same row or different rows, we’ll get the same behaviour.
--start UPDATE transaction and use WAITFOR to delay the COMMIT
BEGIN TRANSACTION
--run update
UPDATE DW.DimProducts
SET ProductName = 'Nokia Windows Phone'
WHERE ProductID = 'D0268';
--force transaction to wait before committing
WAITFOR DELAY '00:00:30';
COMMIT TRANSACTION;
While the SQL runs above, run the next code block in another SQL query window…
--run an immediate update UPDATE DW.DimProducts SET ProductName = 'Samsung Galaxy' WHERE ProductID = 'D0268';
You’ll see that this query executes successfully with 1 row updated, however back in our original UPDATE script it will fail with an error: “Snapshot isolation transaction aborted due to update conflict. Using snapshot isolation to access table ‘DimProducts’ directly or indirectly in database ‘SalesDataWarehouse’ can cause update conflicts if rows in that table have been deleted or updated by another concurrent transaction. Retry the transaction.”
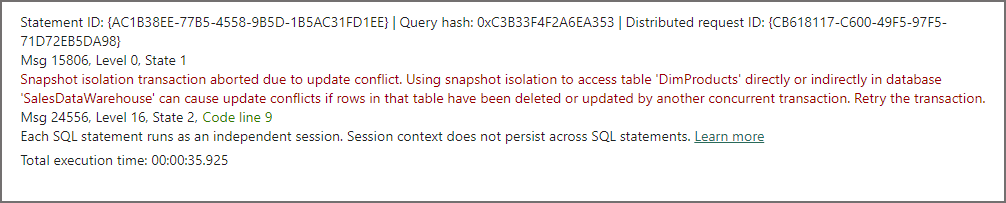
There’s a chance a long running update could be affected if another transaction is initiated after and commits before the long running update. If you expect your workload to have long running updates then it may be worth breaking those updates up into smaller chunks, or not updating at all and using CREATE TABLE AS SELECT…and inserting the changed and unchanged data into a new table.
Inserting Data
The behaviour when inserting data is different to updating/deleting. There’s much less chance of a conflict because when multiple transactions are inserting new data, they are writing to new Parquet files. The lock that is placed on the table is to ensure no schema modifications can take place.
From the MS Docs “INSERT statements always create new parquet files, which means fewer conflicts with other transactions except for DDL because the table’s schema could be changing.”
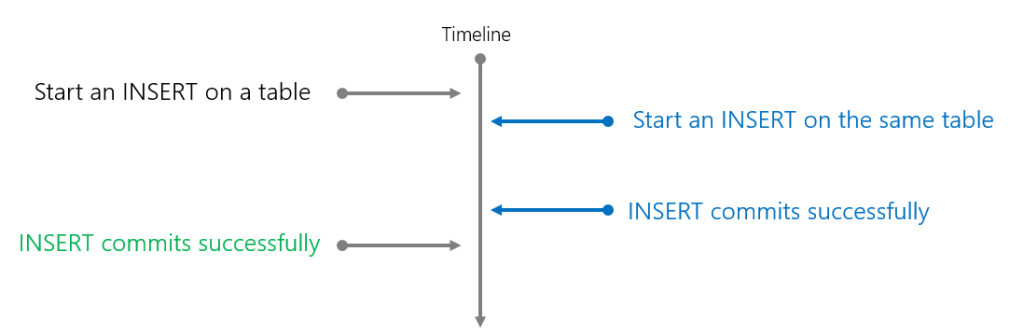
In this scenario we’ll begin a transaction to insert into the DimProducts table, and while that transaction is running, we’ll begin another insert.
--begin transaction for inserting data
BEGIN TRANSACTION
--insert row
INSERT INTO DW.DimProducts
VALUES(4,'Y28734','Mousetrap Board Game')
--use waitfor to delay transaction while the another insert is run
WAITFOR DELAY '00:00:30';
COMMIT TRANSACTION;
While the SQL runs above, run the next code block in another SQL query window…
--insert a row immediately INSERT INTO DW.DimProducts VALUES(5,'P72374','Set of Tables')
Now what happens is that the second insert succeeds and also the first insert succeeds. How’s that for optimism 🙂

Deleting Data
Deletes act the same way as Updates in that if a DELETE transaction is initiated and another DELETE is subsequently begun and committed, the original DELETE transaction will rollback and fail.
--begin a transaction to delete a record and wait while another delete is run
BEGIN TRANSACTION
--run delete
DELETE FROM DW.DimProducts
WHERE ProductKey = 4;
-wait while other statement is run
WAITFOR DELAY '00:00:30';
COMMIT TRANSACTION;
While the SQL runs above, run the next code block in another SQL query window…
--run an immediate delete DELETE FROM DW.DimProducts WHERE ProductKey = 5;
We’ll get the same error as the Update statement: “Snapshot isolation transaction aborted due to update conflict. Using snapshot isolation to access table ‘DimProducts’ directly or indirectly in database ‘SalesDataWarehouse’ can cause update conflicts if rows in that table have been deleted or updated by another concurrent transaction. Retry the transaction.“
If you re-try the original DELETE statement then it will complete successfully.
Monitoring Locks
To monitor the locks that are placed on tables within the Warehouse, we can use the sys.dm_tran_locks DMV to show information about the object and lock type. I like to create a view so I can surface in a Power BI report. You can run the SQL code below to create a getuser function and the view itself. CREATE FUNCTION reference from here.
--get user function
CREATE FUNCTION dbo.getuser
(
@sessionid AS INT
)
RETURNS TABLE
AS
RETURN
SELECT login_name FROM sys.dm_exec_sessions WHERE session_id=@sessionid;
GO
--create lock view
CREATE OR ALTER VIEW dbo.vwSysDMTranLocks
AS
SELECT
DB_NAME(resource_database_id) AS DatabaseName,
OBJECT_NAME(resource_associated_entity_id) AS ObjectName,
resource_type,
CASE request_mode
WHEN 'IX' THEN 'Intent Exclusive'
WHEN 'Sch-S' THEN 'Schema Stability'
WHEN 'Sch-M' THEN 'Schema Modification'
WHEN 'S' THEN 'Shared'
WHEN 'U' THEN 'Update'
WHEN 'X' THEN 'Exclusive'
WHEN 'IS' THEN 'Intent Shared'
WHEN 'IU' THEN 'Intent Update'
WHEN 'IX' THEN 'Intent Exclusive'
WHEN 'SIU' THEN 'Shared Intent Update'
WHEN 'SIX' THEN 'Shared Intent Exclusive'
WHEN 'UIX' THEN 'Update Intent Exclusive'
ELSE request_mode
END AS LockRequestModeDesc,
request_mode,
request_type,
request_status,
request_reference_count,
request_session_id,
resource_associated_entity_id,
getuser.login_name
FROM sys.dm_tran_locks
CROSS APPLY dbo.getuser(request_session_id) as getuser
Then we can query the view and see any current locks and the lock type. If we initiate another UPDATE transaction on the DimProducts table and query the view then we can see the lock type issued.
--select locks on objects
SELECT
DatabaseName,
ObjectName,
LockRequestModeDesc,
request_mode,
request_type,
request_status,
login_name
FROM dbo.vwSysDMTranLocks
WHERE resource_type = 'OBJECT'
AND ObjectName NOT IN ('getuser','vwSysDMTranLocks');

Transaction Notes
The following quick notes are from the Microsoft documentation here on Transactions in Fabric Warehouses, I like to keep this handy as a reference.
- You can group multiple data modification statements into a single transaction
- Lakehouse has isolation in read-only mode
- Snapshot Isolation supported in Fabric (SET ISOLATION statements ignored)
- Cross-database (lakehouse and warehouse) transactions are supported in same workspace
- Supports DDL (eg CREATE TABLE) in transaction
- Locks are at the table level
- Lock types (modes):
- SELECT: Schema-Stability (Sch-S)
- INSERT, UPDATE, DELETE, COPY INTO: Intent Exclusive (IX)
- DDL: Schema-Modification (Sch-M)
- Use sys.dm_tran_locks to see active locks
- If multiple UPDATEs issued on one or more rows in a table then first transaction to commit wins, the others are rolled back with an error. Conflicts are at the table level.
- INSERTs have fewer conflicts as new parquet files are written
- Transaction logging is at the file level, as parquet files are immutable a rollback just points to previous files (transaction logging and rollbacks are quick as it’s a metadata operation)
- Distributed transactions, save points, named & marked transactions are not supported
References
Thanks to Kevin Conan @Microsoft for validating the information within this blog.
Links:
- Transactions in Warehouse tables – Microsoft Fabric | Microsoft Learn
- sys.dm_tran_locks (Transact-SQL) – SQL Server | Microsoft Learn
- Transactions (Azure Synapse Analytics and Microsoft Fabric) – SQL Server | Microsoft Learn
- TRY…CATCH (Transact-SQL) – SQL Server | Microsoft Learn
- All about locking in SQL Server (sqlshack.com)
- ACID Properties in DBMS – GeeksforGeeks
- Lock Scenarios Using sys.dm_tran_locks – SQLServerCentral
- Concurrency Control — Delta Lake Documentation
 Andy
Andy