

Welcome to part 2 in this blog series in which we’re looking at what happens when schema changes are made in source data lake files which is then queried by Serverless SQL Pools in Synapse Analytics. In part 1 we looked at CSV files and several scenarios in which the structure of those CSV files changed and how Serverless interpreted those changes. In this part we’re turning our attention to Parquet files.
If you are new to Synapse Analytics Serverless SQL Pools then you can get started here.


Parquet Format
The Parquet format is an open source file format in which the data is stored in a compressed column-oriented structure, it’s like columnstore indexes in SQL database engines. It’s very useful for analytical/data warehousing workloads as it’s compressed and also supports filter pushdown where only the columns and rows requested in any filtering operations are read from the file.
Parquet files store the data itself plus schema information such as column names and data types plus statistics about columns including min/max values
What’s especially useful about Parquet is that along with the data, each Parquet file also stores schema information such as the column names and data types associated with those columns. It also contains statistics which can be used by a data processing engine to optimise reading and writing. You can read more here.
Scenarios
In the next section we’ll now write out a series of Parquet files and modify the schema each time, we can then observe the results in Serverless SQL Pools. We’ll query a root folder so that all the different Parquet files are read in the same SELECT. For the following scenarios I’ll use the CETAS process to write out Parquet files and amend the schema accordingly.
Initial Dataset
We’ll start by writing out a 4 column schema to a folder in the Data Lake as \raw\events\01\ and then run a SELECT query on root folder \raw\events\*\* to select all folders and files under the root events folder.
SELECT
r.filepath(1) AS Subfolder,
UserID,
EventType,
EventDateTime,
ProductID
FROM
OPENROWSET(
BULK 'raw/events/*/*',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Parquet'
) AS r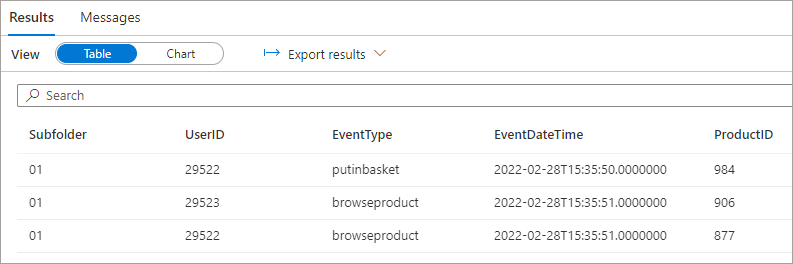
Scenario: Move Existing Column to Different Location
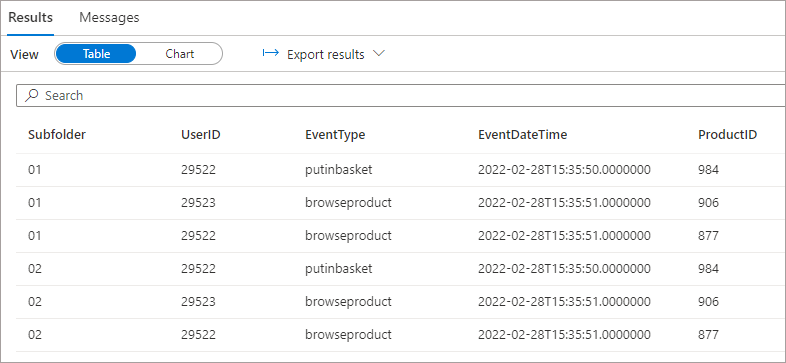
We’ll now write a new Parquet file out to a folder \raw\events\02\ but this time move the UserID column to the end of the Parquet file column ordering when writing the file out. When we run the SELECT over the root folder, we can see that the UserID column is successfully processed and displays the correct values, regardless of the ordering of the columns when writing out to the Parquet file.
Scenario: Remove Existing Column
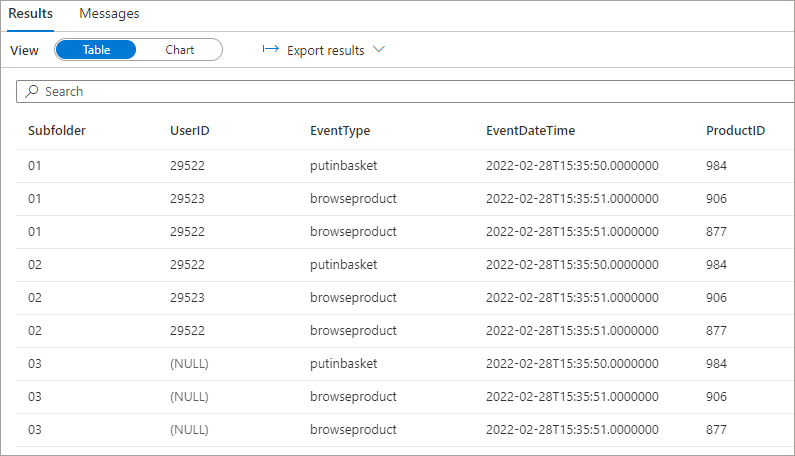
For this scenario we’ll remove the UserID completely from the next Parquet file we write to the folder \raw\events\03 and observe the results. If we run the SELECT over the root folder we can see that the files with the UserID column return those values but NULL is returned for the file(s) without the UserID column.
Scenario: Add New Column
What happens if we now add a new column Device to a new Parquet file and store in folder \raw\events\04? If we add the Device column to the SELECT list, we now get an error stating that Device is an invalid column.
SELECT
r.filepath(1) AS Subfolder,
UserID,
EventType,
EventDateTime,
ProductID,
Device
FROM
OPENROWSET(
BULK 'schemaversion/parquet/*/*',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Parquet'
) AS r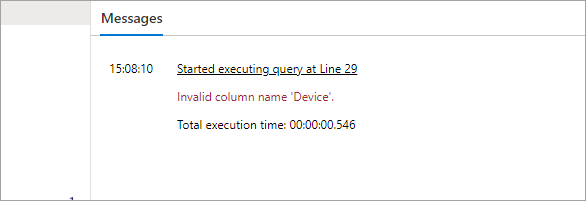
We can use a SELECT * statement (only recommended in Serverless if used with a WITH statement) and although we now get results back, the new column is not returned when running SELECT over the root folder… this happens if the new column is added at the end of the existing columns, or is added in-between existing columns.
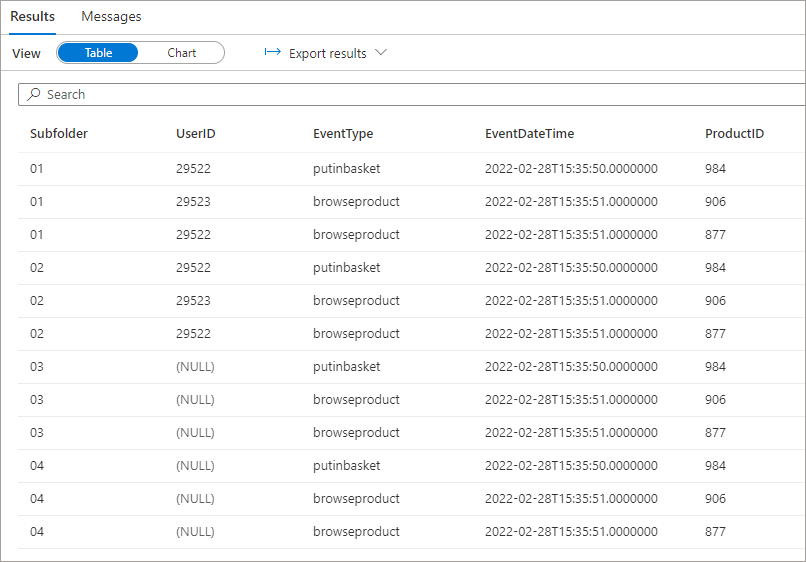
If we modify the BULK parameter in the OPENROWSET statement and specify the \raw\events\04\ folder then we do see the new column being returned but only if we remove the UserID column from the SELECT list. This isn’t very desirable as we lose flexibility to query all folders and we also now lose the UserID column from the other files.
SELECT
r.filepath(1) AS Subfolder,
EventType,
EventDateTime,
ProductID,
Device
FROM
OPENROWSET(
BULK 'raw/events/04/*',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Parquet'
) AS r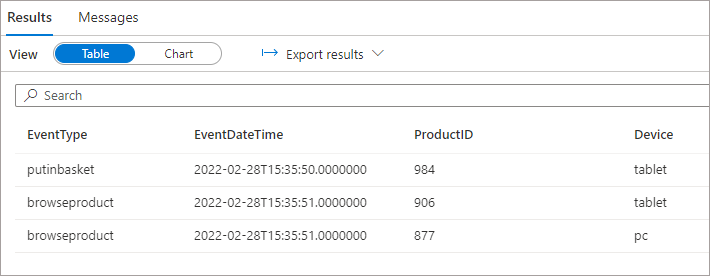
However, what we can do is specify the columns we want in the SELECT statement by using the WITH statement to define the columns. We can still use a SELECT *, we just need to define the columns using WITH. In the following results we can see that Device is defined in WITH and is returned successfully, with all other files showing as NULL.
SELECT
r.filepath(1) AS Subfolder,
*
FROM
OPENROWSET(
BULK 'raw/events/*/*',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Parquet'
)
WITH
(
UserID INT,
EventType VARCHAR(20),
EventDateTime DATETIME,
ProductID INT,
Device VARCHAR(10)
) AS r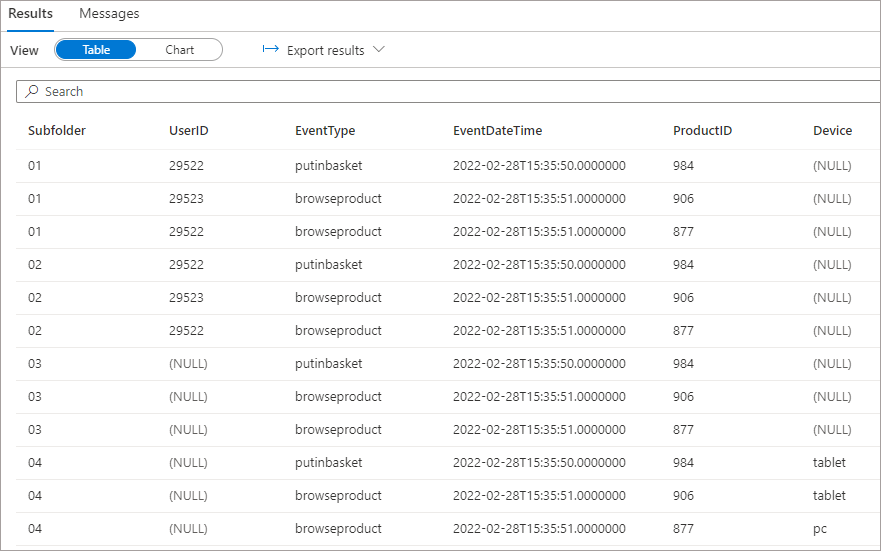
Schema Inference
We can use a system stored procedure to check the schema Serverless SQL Pools discovers when querying the source data when we don’t define a schema using WITH.
EXEC sp_describe_first_result_set
N'SELECT *
FROM
OPENROWSET(
BULK ''raw/events/*/*'',
DATA_SOURCE = ''ExternalDataSourceDataLakeMI'',
FORMAT = ''Parquet''
) AS r'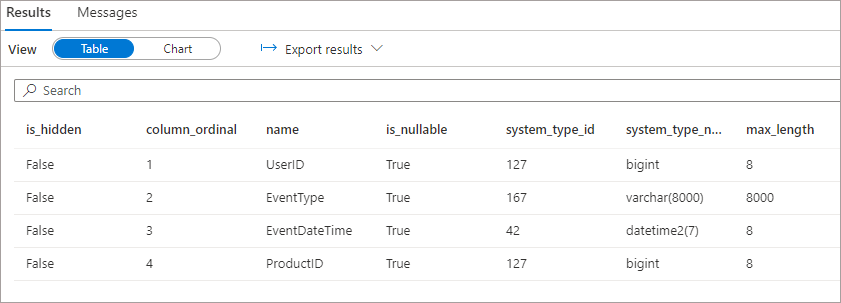
We can see that only the columns defined in the first files in folder \raw\events\01\ are being returned, we don’t see the Device column added in folder \04\ at all.
Conclusion
As we’ve seen in the results above, Serverless SQL Pools can handle situations when schemas change in source Parquet files when queried as a whole, but we must be careful and use the WITH statement to ensure all relevant columns are picked up. This is due to schema inference happening on the first set of files in the subfolder.
In the final part 3 of this series we’ll be looking at the Delta format, which natively supports schema evolution.
 Andy
Andy
[…] automatically handles changing schemas in Delta, unlike the behaviour in CSV (part 1) and Parquet (part 2) in which we did encounter undesirable […]