

Overview
This is the second part of the Fabric Warehouses for DBAs blog series, if you haven’t read the first part which is an overview of the series and includes all the areas we’ll cover, please click here.
In this second part we’ll start with describing the overall Microsoft Fabric (here-in referred to as Fabric) product and then dive into the Warehouse service itself. In my opinion asking “What is Fabric?” is as difficult a question to answer as “What is Car?” Fabric is many things, it’s the umbrella term to denote a product that has many facets. I find the best way to approach Fabric is to first have an overall view of what the Fabric concept is but then approach is from a specific role. Are you a Data Engineer? Are you a Data Analyst? Machine Learning Specialist? DBA? Sysadmin? Network Guru? The list goes on and you may find approaching “learning Fabric” with a broad brush overwhelming. I’ve been working with the product for over a year now and I still feel and will continue to feel overwhelmed.
No-One is a Fabric Expert
No-one is a “Fabric” expert (great post by Kurt Buhler). Maybe if there were 48 hours in each day, and you dedicated your entire time to dive into every facet of Fabric, then maybe you can become an “expert in all Fabric things.” It’s highly unlikely, and also don’t put that pressure on yourself. As an example, as the Power BI surface area grew, who could be a expert in all the areas? Maybe some folk were, but who could be an expert in Administration, Security, DAX, M, Data Modelling, Visualisations, Networking? Any one of those areas can consume an inordinate amount of time. Fabric is the same. We need to approach Fabric from a real-world role perspective and identify the areas of interest per role.
If I were to compare SQL Server to Fabric, well SQL Server has a lot of services and features available. So can someone be a “SQL Server Expert” and know all about the SQL engine, SSAS, SSRS, Security, T-SQL? SQL Server is a big product and complex, covering a lot of capabilities from transaction line of business to data warehouses to data integration. While it might be challenging for one individual to master every aspect thoroughly, SQL Server experts typically concentrate in areas such as performance tuning, security, or data warehousing. Some folk have dedicated their time to being an expert in all things SQL Server.
What Is Fabric?
Let’s get started…What is Fabric? This is a question many blogs have presented over the last year. Fabric is Microsoft’s new Software-as-a-Service Data and Analytics platform. It combines the Power BI service with new workloads including Spark compute for Data Engineering, a SQL engine for Data Warehousing, Data Factory for data ingestion and processing, Realtime Streaming using Kusto, and a common Data Lake Gen2 service called OneLake which all these services use to store data. This means that a Spark Data Engineering process which saves data to OneLake can be access by other services. It’s this interoperability of the stored data that makes Fabric compelling.
In essence, you can built an entire end-to-end data platform in Fabric, from loading data from source systems, to cleansing/formatting and storing this data, then modelling for analysis, and building and distributing reports. All in one ecosystem.
All of this is hosted in the cloud and managed by Microsoft, and this is the big departure from a platform such as SQL Server, you’re not actually installing software on hardware (or virtual hardware), you’re accessing a URL when working with all these workloads in Fabric. Microsoft is managing the compute (which we’ll go into more detail in part 3 of this series) and looking after the service for you.
I promise to keep the “Microsoft Marketing Slides” to a minimum, but I should include the stock Microsoft Fabric slide so you can become familiar with the terms and icons used. In this series we’re looking at the Warehouse service specifically, but may touch on other services such as Data Engineering as we’ll discuss the Lakehouse SQL Endpoint as well.
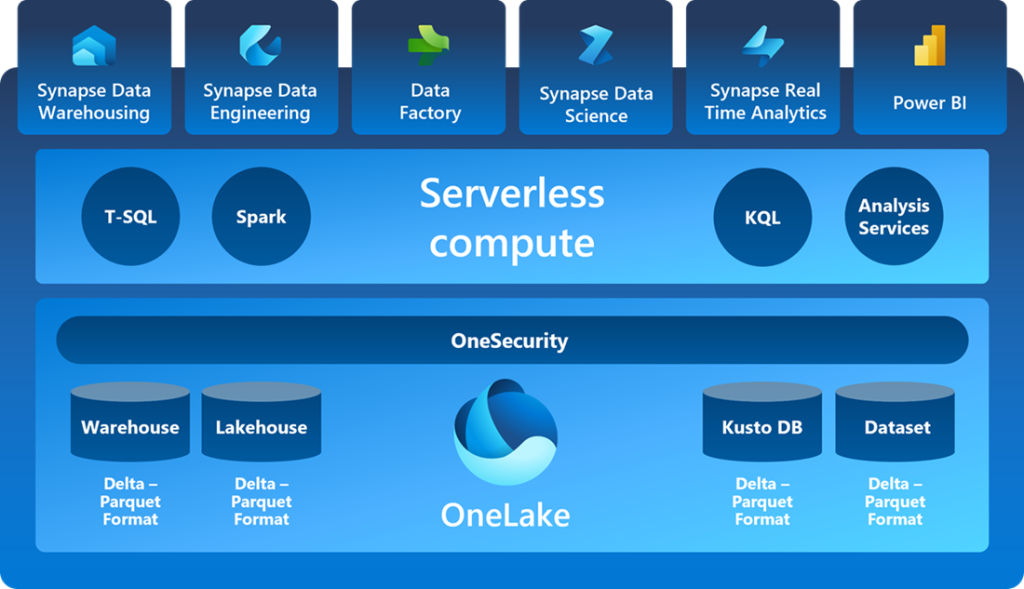
Accessing Fabric
If you want to get hold of a SQL Server edition it’s pretty easy, you can visit the SQL Server download page here and just download a Developer licensed edition, install on a PC and away you go. It’s different in Fabric in that we need a company email (personal emails are not supported) to access the service, therefore if you have access to a company email then you can sign-up for Fabric via the URL https://app.fabric.microsoft.com/ (or the Power BI URL https://app.powerbi.com/)
If your company is already using Power BI then signing in should be straight-forward, you may need to contact your local friendly Power BI Administrator about your user licensing (e.g. Power BI Pro licenses are required if you wish to author Fabric items).
If you wish to access Fabric yourself outside of your company, then you will need to create an Entra tenant in which to then access Fabric via a “company” email. This used to be possible for free via a Microsoft 365 Developer account but this has since been rescinded. The process I have followed recently is:
- Use your personal email (or create a new Outlook email)
- Login to https://portal.azure.com and proceed through the steps to create a new account
- This does require entering a credit card, but when activating a Fabric trial you do not need to spend a single penny
- Once the new Azure account has been created, browse to the Microsoft Entra ID section in the portal
- Click Users and create a new user, you can then use this new user which will have a name something like newuser@myemailaddressoutlook.onmicrosoft.com
- Login to https://app.fabric.microsoft.com/ using this new email
Software-as-a-Service
When describing what Software-as-a-Service (SaaS) is, it’s usually compared to the other technology deployment options, Platform-as-a-Service and Infrastructure-as-a-Service. Basically it’s all about control…who is going to be looking after the service itself? E.G. if we install SQL Server on a server in a data centre or an Azure Virtual Machine (VM) we’re using the IaaS model, if we use Azure Managed Instance or SQL Database, we’re using PaaS. With Fabric SQL, we’re using SaaS.
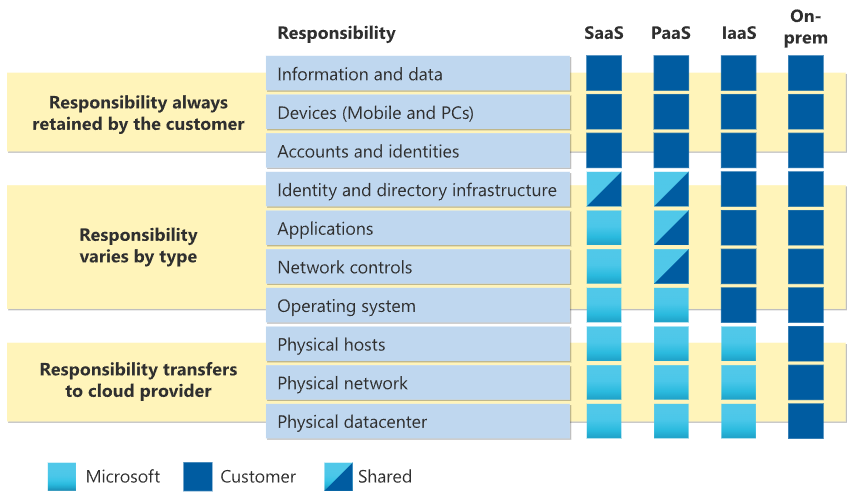
Examples
In terms of the variety of data services in Azure, the following table shows an example of products and services and which model they are aligned to.
| SaaS | PaaS | IaaS |
|---|---|---|
| Fabric SQL Warehouse | Synapse (Dedicated & Serverless SQL Pools) | SQL Server |
| Fabric Lakehouse | Azure SQL Database | SSIS (Integration Services) |
| Power BI | Azure Data Factory (inc. SSIS) | SSAS (Analysis Services) |
| SQL Server Managed Instance | Reporting Services |
What is the Fabric Warehouse Service
Put simply, Fabric Warehouses are a SQL database created within Fabric. When creating a Warehouse in Fabric, you’re basically creating a database inside the Power BI/Fabric Workspace you specify (more on Workspaces later). However this isn’t a database found in other services like Azure SQL Database and SQL Server. The Warehouse service is driven by a SQL engine which is a distributed query processing engine, it’s an enhanced version of the Synapse Serverless SQL Pools engine which gives you CREATE/ALTER/SELECT/INSERT/UPDATE/DELETE etc. functionality (although there are syntax limitations). The table storage itself is managed by Delta Lake which provides transactional consistency (ACID) and data is stored in Parquet files. We’ll be diving into the storage in part 4 of this series.
As it’s SaaS, you have very little control over the underlying Warehouse service. There are currently no configurations in terms of compute power, other than the overall Fabric Capacity Units (we’ll go into more detail in the next blog – Compute). It can be very disconcerting if coming from a SQL Server (or other database platforms) background as there’s not a lot that can be configured, you are trusting Microsoft to run workloads in an acceptable timeframe. That lose of control can be daunting.
Whilst it’s not SQL Server, it has some aspects carried over such as certain DMVs like sys.databases and others for viewing metadata and query history. It does not have all the features of SQL Server, which is a very feature rich application. The Fabric SQL engine is designed for analytical purposes only, row by row really does become row by agonising row. You won’t be building line-of-business/highly transactional systems in the Fabric Warehouse service.
In terms of ingesting data into the Warehouse, the supported data ingestion methods are:
Workspaces Are Like Servers
Within the Power BI/Fabric portal, items like Power BI Datasets, Reports, Dashboards etc. need a Workspace to live in. These Workspaces are also where the Fabric items like Warehouses live. I think of Workspaces like an individual SQL Server instance, each Workspace has a unique SQL URL to connect to. SQL clients such as SSMS, Azure Data Studio can connect to this endpoint.
When you create a “Warehouse” in a Power BI/Fabric Workspace, you are essentially creating a database. In-fact if you connect to the Workspace SQL Endpoint URL, any Warehouses (and Lakehouses) in that Workspace show as Databases. With Workspaces there is also a compute boundary between Workspaces, more on this in the Compute blog.
E.G. in the screenshot below, I have a number of Warehouses within a single Workspace.
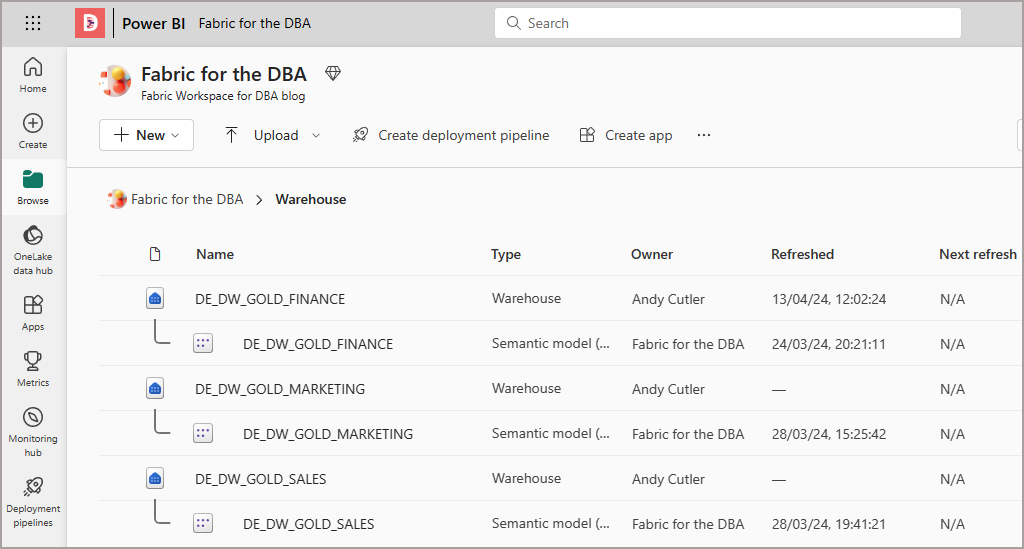
If I connect to that Workspace SQL URL I can browse the Workspace like a SQL Server and see the Warehouses (and Lakehouses) as databases. To find the Workspace SQL URL, click the ellipsis on a Warehouse and click Copy SQL Connection String.
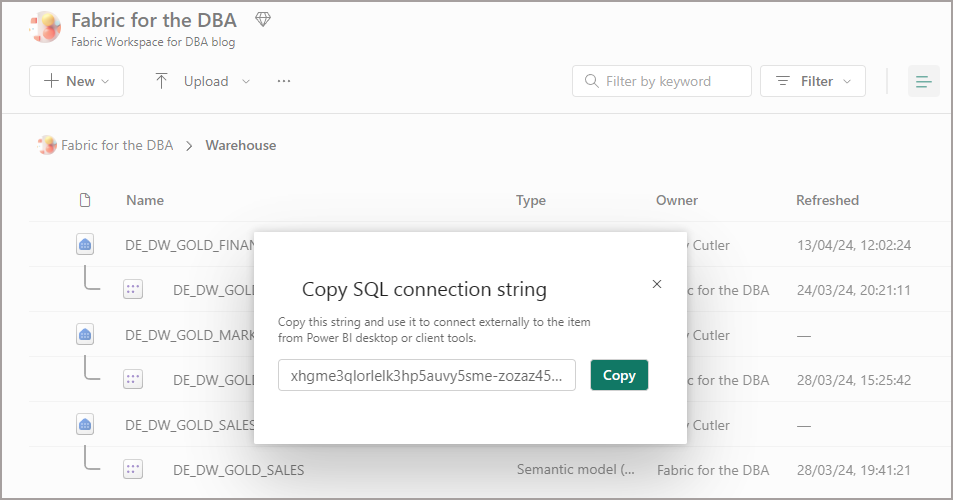
In the example below, I’ve logged into the Fabric Workspace in SSMS using the SQL Connection string and can see the “Warehouses” and also “Lakehouses” as databases.
Star Schema (All The Things)
In terms of what the Warehouse service is primarily useful for is data warehousing workloads. The tried and tested dimensional model is alive and well, and is suited for use in the Warehouse service. Dimensional models (star schemas) are a specific type of table layout in a database where tables are divided between 2 types: Dimensions and Facts. Dimensions are used to house reference data and are typically smaller in size than Fact tables. Fact tables are typically used to house activity/event/transaction data and are linked to Dimension tables. The diagram below shows a basic logical layout of a star schema.
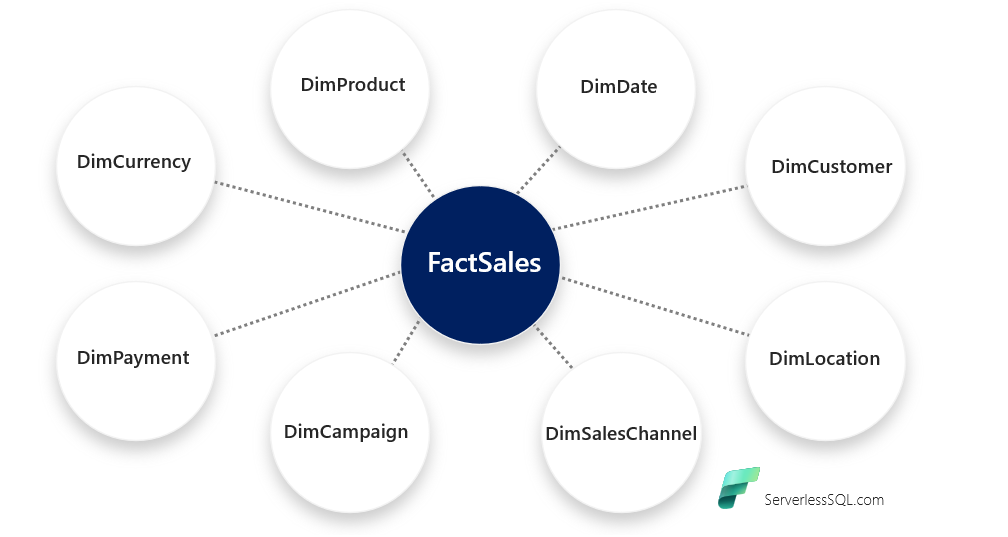
Thanks to Koen for the Star Schema All The Things term.
Evolution to Fabric SQL
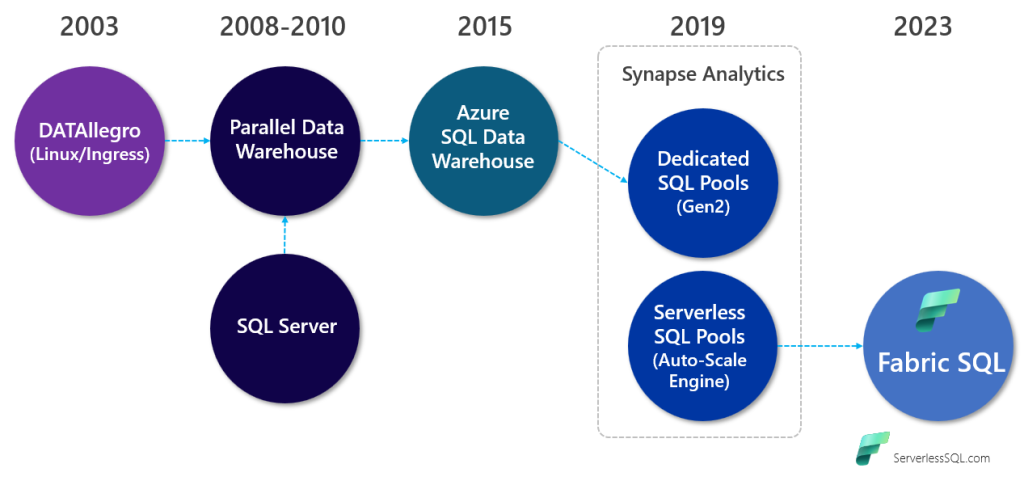
How did we get here? Well it starts (from my perspective) back in around 2003 when Stuart (Stu) Frost started a company called DATAllegro to compete with the large scale data warehouse vendors of the day like Netezza and Teradata. DATAllegro used an open source software stack Ingres database on Linux. Microsoft then purchased DATAllegro and went onto build SQL Server Parallel Data Warehouse (PDW) around 2008. However, this only ran on specific hardware by specific vendors (Dell and HP). PDW then became Azure SQL Data Warehouse, which was a whole lot easier to spin up as it became a PaaS service.
In 2019 Azure Synapse Analytics (PaaS) was announced, bringing together disparate services to create a unified data platform (sound familiar?) and that included rebranding Azure SQL Data Warehouse as Dedicated SQL Pools and also introducing a new SQL engine, Serverless SQL Pools (Polaris). However, Azure Synapse Analytics provided a challenge in terms of data footprint. You either need to have “big data” for Dedicated SQL Pools as it really was still a specialist warehousing platform, or you invested in Spark workloads to create Lakehouse architectures. I myself appreciated the Serverless SQL Pools service in that it dealt well with data of all sizes, so even a “SQL first” developer like me could get any size data in a Data Lake and use Serverless SQL Pools to analyse. However, it wasn’t really a data warehouse service per-se so it was very tricky to migrate a whole data warehouse solution just to the Data Lake and use Serverless SQL Pools. Not impossible, but tricky.
SQL Engine Evolution
Here’s the timeline for the SQL engine evolution.
Why Would An Organisation Purchase Fabric?
So why would an organisation choose Fabric? Well there are a lot of positives here, but only if it suits an organisations requirements. Fabric encompasses a lot of services, and is probably not suited to those looking for a single data service. I can’t see the benefit to organisation buying Fabric just for a single service.
Reduce Complexity
The idea of having “all data services in one place” is quite alluring for an organisation who wishes to reduce complexity, development & deployment time. We have for several years been very busy drawing lots of boxes and arrows between Azure services to provide a holistic data infrastructure, this infrastructure comes with complexity in terms of getting the various disparate services to communicate with each other. An Architects dream and it worked well when it worked and of course still does and will continue to do so.
In Fabric, the number of items may not actually decrease, but the interconnectivity between the services becomes a lot simpler. The image below is quite extreme but it serves as a great example of all the different Azure services that could be used to stitch together an overall analytics platform.
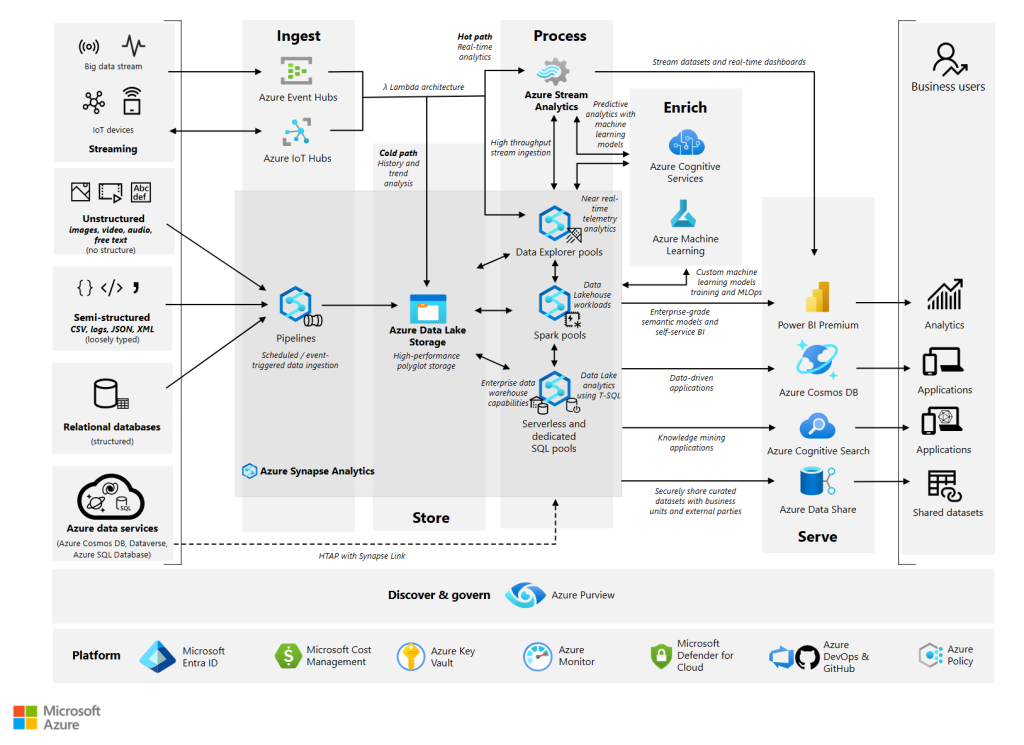
However if an organisation wishes to have greater control over individual data services then Fabric may not be the best choice. With SaaS you do lose control to a certain degree, and that model may not suit certain organisations and their data platform requirements.
Greater Team Collaboration
With a common interface, teams across Engineering, Analysis, Machine Learning, and DevOps can now collaborate in a service that shares experiences and with OneLake, storage across services becomes easier for teams to access (with relevant security of course).
Leverage Existing Investment
If an organisation already use Power BI and especially Premium, this now gives them an option to migrate Data Engineering and Data Warehouse workloads into the service. As a caveat, although Power BI Premium (P SKUs) support Fabric functionality, not everything is supported such as networking security features. And Microsoft will be phasing out Premium P SKUs in the not too distant future (starting in 2025).
Next Blog
In the next part of this series we’ll be diving into the Compute and SQL Engine so please stay tuned.
Disclaimer
For disclosure I am a Microsoft Data Platform consultant who has been working predominantly with Microsoft technology for most of my career. I’m a current Microsoft Data Platform MVP and as such I have early access to private preview features and services. The thoughts and opinions in this blog are my own. Your usage of the contents of this blog is at your discretion. Always validate what you read, no matter the source.
References
If you’d like to dive into more reading then the following list can be useful:
- What is Microsoft Fabric – Microsoft Fabric | Microsoft Learn
- What is data warehousing in Microsoft Fabric? – Microsoft Fabric | Microsoft Learn
- Shared responsibility in the cloud – Microsoft Azure | Microsoft Learn
- Analytics end-to-end with Azure Synapse – Azure Architecture Center | Microsoft Learn
- Implement medallion lakehouse architecture in Microsoft Fabric – Microsoft Fabric | Microsoft Learn
- Data warehouse tutorial – introduction – Microsoft Fabric | Microsoft Learn
- Understand star schema and the importance for Power BI – Power BI | Microsoft Learn
- DATAllegro – Wikipedia
- Polaris Whitepaper: vldb.org/pvldb/vol13/p3204-saborit.pdf
 Andy
Andy