

When using Serverless SQL Pools to write data to Azure Storage/Data Lake Gen2 using the CREATE EXTERNAL TABLE AS SELECT (CETAS) syntax, the number of source rows and size of the data will have an impact on how many destination files will be created and how many rows per file will be written. In previous posts we have looked at creating a Logical Data Warehouse which included reading source CSV data and then writing that data back to Azure Storage in Parquet format. The reason for writing the source data out as Parquet is to benefit from the formats compression to reduce data size (and therefore costs due to reduced data processed) and to increase read performance.
Currently there are no options in Serverless SQL Pools to modify or override CETAS behaviour when writing to Azure Storage therefore the Parquet files will be written out to a single folder location and depending on size will be split across multiple files.
Scenario
We’ll be using the source Sales Order Lines data created during Part 1 of the Logical Data Warehouse series, however a larger amount of data has been generated for the purpose of the blog post. To test different row loads, the source data has been multiplied during the SELECT process.
For each row load, the data will be read from the source CSV data and written to Azure Data Lake Gen2 using CREATE EXTERNAL TABLE AS SELECT. After the results have been noted, the External Table created during the process will be dropped and the written Parquet file data will be deleted.
Source Data
Details of the source data are as follows:
- CSV file format
- ~50 Million rows
- ~6 months of data written to a Year/Month/Date folder structure in Azure Data Lake Gen2
- ~5GB data footprint
Example
Here is an example of the source data.

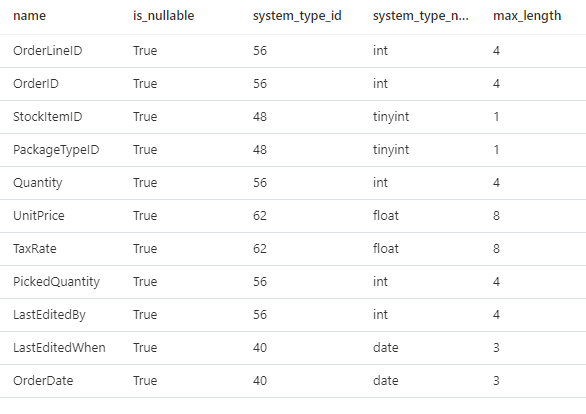
Data Types
Here are the data types assigned to the source data.
CETAS Results
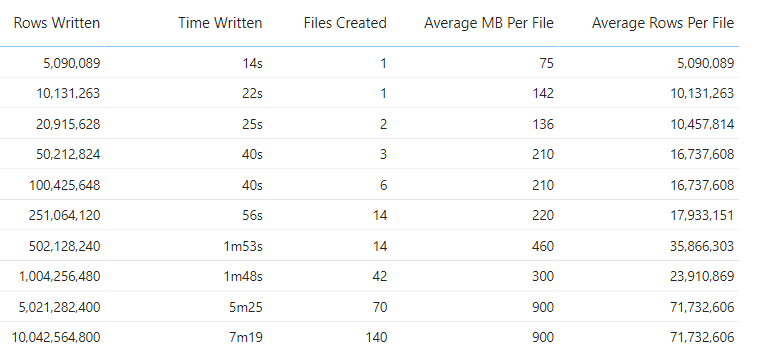
The following table provides a breakdown of how many source rows were written during the CETAS process, the time taken to write those rows, how many individual Parquet files were created, the average MB size of each file, and the average row count per file.
The following graph shows how many source rows were written during the CETAS process, the average MB per Parquet file and how many files were created.
Conclusion
We can see when the number of rows hits 20 Million, multiple files are created. The average file size of each Parquet file remains roughly the same at ~210MB between 50 Million to 251 Million rows before growing as the number of rows increases. What’s interesting is that 500 Million rows were written out to the same number of files as 251 Million with a large jump in average file size, before dropping in size for 1 Billion rows.
5 Billion and 10 Billion rows kept the same average file size of 900MB (and average row count per file of 71 Million) but the number of files doubled from 70 to 140.
A particular set of source data and data type attributes may show different results when written to Parquet by Serverless SQL Pools. The results shown here may differ when compared to other source data.
Cost
To provide transparency with regards to cost the total amount of data processed when reading and writing the 10 Billion row scenario was ~1.3TB (source CSV data and destination Parquet data) with a cost of ~$6.5.
 Andy
Andy