

The slides for the DataMinutes #2 session Turbocharging Power BI using Synapse Analytics is available here to download.

GitHub Code
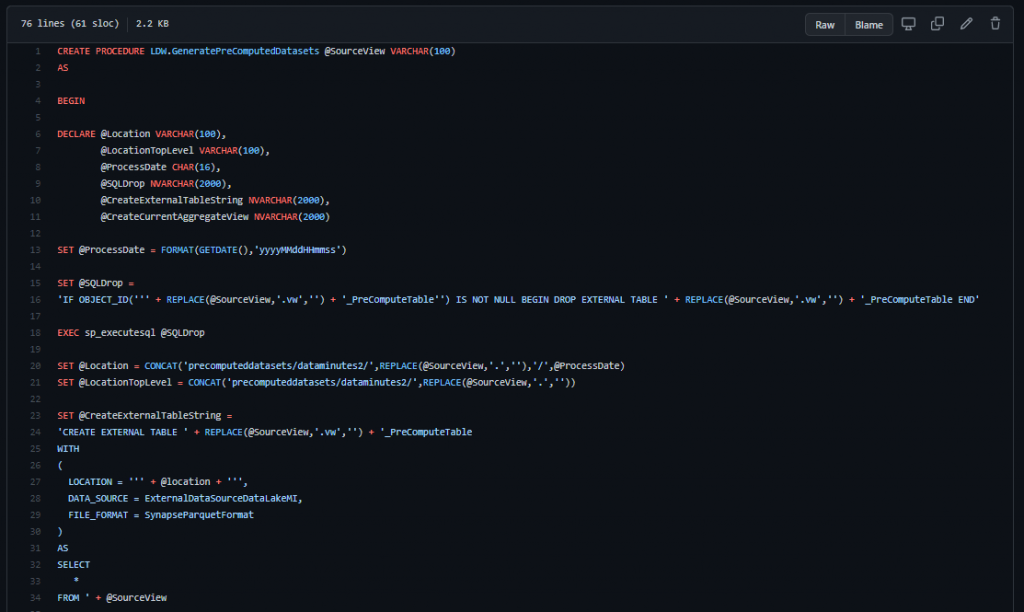
The Serverless SQL Pools code to generate the pre-computed datasets is available on GitHub here.
The SQL code creates a stored procedure which is used to generate a dataset in the data lake using the CETAS process. It takes an existing View name as a parameter and exports the results of the View to a new datetime stamped folder in the data lake. It also creates a view which then selects only the current folder data.
You can think of this process as being similar to a Materialized View in Dedicated SQL Pools, however the stored procedure needs to be executed to run the process. A trigger for this could be an activity in a Pipeline/Data Factory when source data changes.
 Andy
Andy