Delta Lake Change Data Feed in Fabric Lakehouses
As I start to look at how to architect and develop data solutions using Microsoft Fabric, I come back to the thought in my head of how to detect changes in data upstream, and also to detect the type of change that occurred. I can then use that information downstream to dictate what happens when loading data. One of the things that I’ve been looking at more and more is using the features that Delta Lake provides. Yes, Microsoft Fabric is new but Delta has existed longer, and we can use those features in code within Fabric Notebooks.
Change Data Feed (CDF) feature allows Delta tables to track row-level changes between versions of a Delta table
Delta.io
There’s a feature in Delta called Change Data Feed and I was interested about trying it in Fabric to identify changes in source data so that I can then decide what to do downstream. The CDF feature isn’t exactly new, it’s been around for a couple of years now and of course we’re not dealing with anything Microsoft has created specifically for Fabric, this is a feature available in OSS Delta.
The use cases for CDF are:
- The Delta table has Updates and Deletes, not just Inserts (append-only).
- Small % of records in the table are modified
- Incremental data is loaded into the table (not truncate/reload)
As you can see, it’s not suitable for all scenarios, e.g. if you truncate and reload a table, or if a large % of the table rows are modified.
Notebook code is available on GitHub here.
Walkthrough
What we’ll do in this blog post is:
- Create a new Lakehouse in Fabric in an existing Workspace
- Create a new Notebook in this Workspace and attach to the Lakehouse
- Create a Dataframe and save as a Delta table to a Lakehouse
- Insert a new row
- Update an existing row
- Delete an existing row
- Query the Change Data Feed
- Evolve the table schema by adding a new column
- Query the Change Data Feed again to observer results
- VACUUM the table and observe the results
Prerequisites
- Access to Microsoft Fabric
- A Workspace allocated to a Fabric capacity
- A Power BI Pro licence to create Fabric content
Create Lakehouse and Notebook
We’ll create the Lakehouse which will be used to store the Delta table we’ll work on, and also a Notebook associated to this Lakehouse. We’ll then work exclusively in the Notebook for all the CDF functionality and querying the table.
- Login to https://app.powerbi.com (or https://app.fabric.microsoft.com/)
- Either browse to an existing Workspace assigned to a Fabric capacity (e.g. Trial) or create a new Workspace and assign to a capacity.
- In the Workspace, select the Data Engineering experience in the bottom left menu
- Select New > Lakehouse and give it a name
- Once created, click New > Notebook and give it a name (click the default name in the top left to change)
- In the left menu, click Add under Add Lakehouse and add the lakehouse just created
Enable All New Tables for CDF
We can set a property to enable all new tables to be created with CDF features enabled. We’re also able to specify whether a table is created with the CDF feature enabled, and also alter an existing table to switch the feature on. All the following code is executed in a single Notebook in a Fabric workspace connected to a Lakehouse.
Run the configuration setting below in the Notebook.
#config to enable all new Delta tables with Change Data Feed
spark.conf.set("spark.microsoft.delta.properties.defaults.enableChangeDataFeed", "true")
Once the feature has been enabled, all new Delta tables created in the Lakehouse will have the CDF feature enabled.
Create and Load Dateframe
Let’s now create some data in a Dataframe and save it to a Lakehouse table. The following code creates a schema with 5 columns and creates a Dataframe with 3 rows of data.
#import data types
from pyspark.sql.types import *
from datetime import datetime
#create schema
table_schema = StructType([
StructField('OrderID', IntegerType(), True),
StructField('ProductName', StringType(), True),
StructField('ItemPrice', IntegerType(), True),
StructField('OrderTotal', IntegerType(), True),
StructField('OrderDate', DateType(), True)])
#load rows
staged_rows = [(1,'Soft Toy',10, 35,datetime(2023, 11, 20)),
(2,'Mobile Phone',450, 10,datetime(2023, 11, 20)),
(3,"Notepad",5,125,datetime(2023, 11, 20))]
#create dataframe and append current datetime
staged_df = spark.createDataFrame(staged_rows,table_schema) \
.write.mode("overwrite").format("delta").save("Tables/rawproductsales")
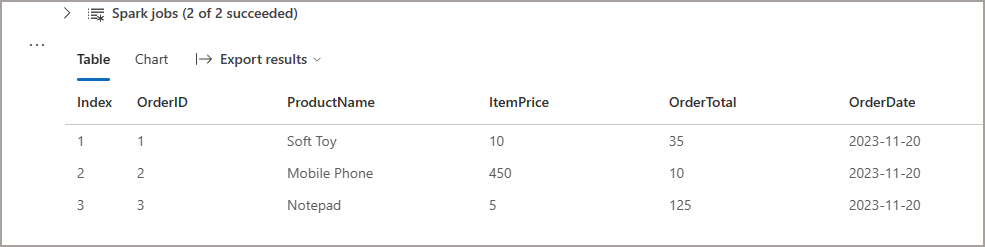
Once the table has been saved, we can query it and see we have 3 rows in the newly created table.
#read data
df = spark.read.format("delta").table("rawproductsales")
display(df)
Modify Table Data
Now that we’ve created the table, let’s modify by inserting, updating, and deleting data.
INSERT into table
Let’s insert a new row into the table, keeping the same columns as before.
#add new order
new_order = [(4,'TV',2, 750,datetime(2023, 11, 21))]
spark.createDataFrame(data=new_order, schema = table_schema).write.format("delta").mode("append").saveAsTable("rawproductsales")
UPDATE table
Now let’s UPDATE an existing row in the table and change the ItemPrice and OrderTotal values for a single order.
#update existing order
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark, 'Tables/rawproductsales')
# Declare the predicate by using a SQL-formatted string.
deltaTable.update(
condition = "OrderID = 1",
set = { "ItemPrice": "9", "OrderTotal": "38" }
)
DELETE from table
Finally, let’s DELETE an existing order from the Delta table.
#delete existing order
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark, 'Tables/rawproductsales')
# Declare the predicate by using a SQL-formatted string.
deltaTable.delete("OrderID = 2")
Let’s read the table again and we can see the new order (OrderID 4) exists, OrderID2 has been deleted, and OrderID1 has been updated.
#read latest data
df = spark.read.format("delta").table("rawproductsales")
display(df)

Great, so we’ve got our most recent data. We could use Delta’s time travel to go back in time and check values of the table at specific points in time. However, can we use the CDF to look not only what the changes are but what action caused the changes (INSERT, UPDATE, DELETE).
Query the Change Data Feed
We could always add our own timestamp column to get the latest data for any downstream process (and would probably still be very useful), so what’s the use of CDF? Well, there are metadata columns added to a CDF table which we can use to query based on the actual action that was done on the row (INSERT, UPDATE, DELETE). We can query the CDF based on Delta commit versions and timestamps.
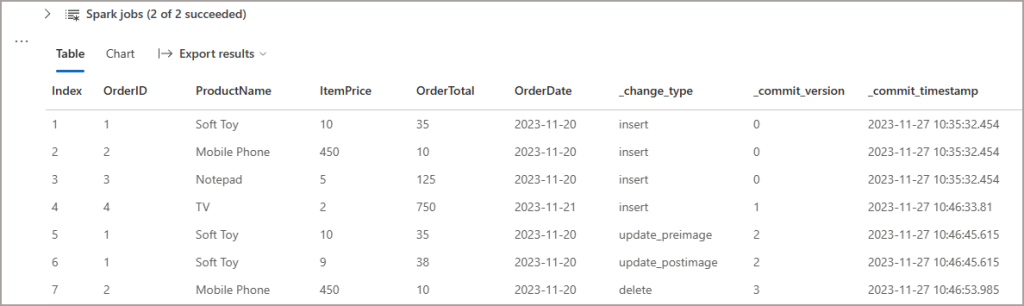
If we query the table using the readChangeData (table_changes in SQL) function, we can start to query the table at specific Delta log commit versions and points in time and see what action the row has assigned to it. This can then dictate what we do further downstream for processing.
I’ll use the commit version by specifying startingVersion 0 in the Dataframe options, this will return all the changes since the table was created.
#read change data feed
changedatefeed_df = spark.read.format("delta") \
.option("readChangeData", True) \
.option("startingVersion", 0) \
.table('rawproductsales')
display(changedatefeed_df.sort("_commit_version"))
In the results, we can see metadata columns including:
- _change_type: the action of the row. For UPDATES there is a pre and post changes logged.
- _commit_version: The Delta log commit version
- _commit_timestamp: The Delta log commit timestamp
Let’s switch to SQL and use the table_changes function to query the table and specify the action of the rows we want to return.
Updates Only
%%sql
--get the updates only
SELECT *
FROM table_changes('rawproductsales', 1)
WHERE _change_type ='update_postimage'

Deletes Only
%%sql
--get the deletes
SELECT *
FROM table_changes('rawproductsales', 1)
WHERE _change_type ='delete'

Inserts Only
%%sql
--get the inserts
SELECT *
FROM table_changes('rawproductsales', 1)
WHERE _change_type ='insert'

What About Schema Evolution?
What happens if I change the schema using the mergeSchema option when writing a Dataframe with new columns to the existing table? The documentation talks about different Delta version supporting this, but with caveats. I’m using Delta 2.4 in Fabric Spark (recently released as of November 2023).
#add new order
new_order = [(5,'Laptop',699, 2,datetime(2023, 11, 22))]
#add new column for discount percentage
df = spark.createDataFrame(data=new_order, schema=table_schema) \
.withColumn("DiscountPercent",lit(10))
#write to table
df.write.mode("append").format("delta") \
.option("mergeSchema", "true") \
.save("Tables/rawproductsales")
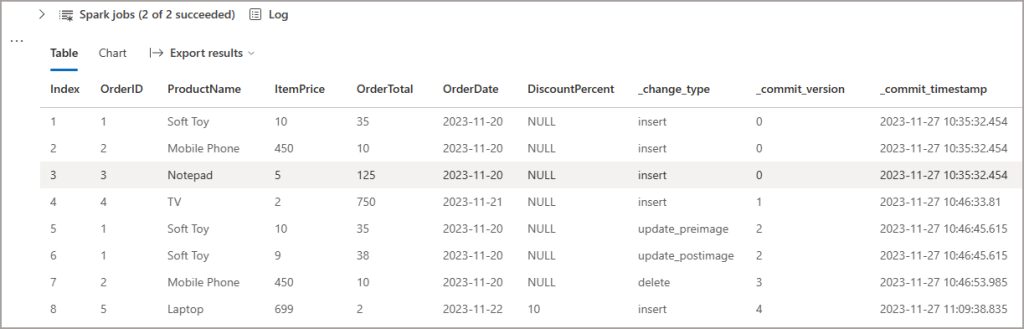
If we run the same command from earlier to get all the changes, we can see the column has been added successfully.
#read change data feed again
changedatefeed_df = spark.read.format("delta") \
.option("readChangeData", True) \
.option("startingVersion", 0) \
.table('rawproductsales')
display(changedatefeed_df.sort("_commit_version"))
Beware When Vacuuming
CDF is affected by running VACUUM on the table, after all CDF is really working with the Delta log and the commit metadata. If you remove this then there’s nothing for CDF to go back to and check.
I’ll set an option to aggressively vacuum the table and leave nothing behind other than the most recent commit.
#set aggressive vacuum
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
#vacuum table and remove all commits except latest from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/rawproductsales') deltaTable.vacuum(0)
If we query the table changes now and keep the same startingVersion 0 we’ll get an error returned. I won’t post the error here but it’s very loooong and asks you to REFRESH the Delta table, but this never works when I query the table changes again.
#display latest (and only) commit and changes using startingVersion
changes_df = spark.read.format("delta").option("readChangeFeed", "true").option("startingVersion", 0).table("rawproductsales")
display(changes_df.sort("_commit_version"))
This time I’ll use the startingTimestamp and specify a datetime, I may get an error stating valid datetime ranges that can be used.
#display latest (and only) commit and changes using readChangeData
changes_df = spark.read.format("delta") \
.option("readChangeData", True) \
.option("startingTimestamp", '2023-11-27 19:00:37.195') \
.table('rawproductsales')
display(changes_df.sort("_commit_version"))
I did set the timeStampOutOfRange setting, but this had no impact on returning errors.
#set config, this doesn't seem to work
spark.conf.set("spark.databricks.delta.changeDataFeed.timestampOutOfRange.enabled", "true")
Conclusion
So there are caveats when using the Change Data Feed with a Delta table and should only be used in certain workload scenarios, but it seems super useful to me to be able to query a Delta table and extract specific action types and then I can decide what to do downstream.
As always feel free to reach out to me to discuss anything in this blog, and thanks for reading.




