

This blog will be split over 2 parts, in this first part we’ll look at the medallion architecture from the perspective of Microsoft Fabric implementation, (check a new doc from MS on the subject here). What I’ve been interested in looking into is what options we have in data processing within Fabric and what is/isn’t possible, as during my own testing I have found there are caveats and ways of working with these options. This is just my thoughts as I’ve been working through it.
Part 2 will then look at actually building an end-to-end solution using the methods and principles outlined in this first part.
Overview
Let’s start with a statement…I’m not here to talk about what the Medallion Architecture is, and debate its terminology and naming conventions (all that Bronze, Silver, & Gold zone-naming terminology). However, I’ll likely use the medallion terms and other zone names interchangeably. At the root of this, all the zone names do is describe a basic overall data quality process as data moves through zones (stages) from source systems to business analysis & reporting.
| Medallion Term | AKA | What’s it for? |
|---|---|---|
| Bronze | Raw | Storing your source systems data unchanged, unclean, contain duplicates |
| Silver | Cleansed | Storing de-duplicated, cleansed, missing values replaced, same grain as source bronze/raw data |
| Gold | Curated | Storing data modeled for analysis e.g. Star Schema, Aggregate tables. This is the highest quality data ready for reporting |
The number of these zones and the names of these zones may be different for different organisational needs (please watch Simon Whiteley’s video on the subject here, essential viewing). E.G the Bronze (Raw) Zone could be made up of multiple copies of the data going through different “raw” stages. You could also add a Platinum zone if you wish for your very, very best data!
As someone who spent time looking at basic implementations of the Medallion Architecture in Synapse Analytics, how is it implemented in Microsoft Fabric? Synapse is Platform-as-a-Service (PaaS) whilst Fabric is Software-as-a-Service (SaaS) and as such I’m wondering if we lose any control over how we can implement the various zones that make up the medallion architecture. I understand how to do it with Synapse by either creating a single or multiple Azure Data Lake Gen2 (ADLS Gen2) accounts (see my blog here about OneLake vs ADLS Gen2). But now we’re in a “unified service with unified storage” world, how do we set the structure up?
There’s a recent article here from Microsoft, talking about Implementing Medallion Lakehouse Architecture in Microsoft Fabric. I won’t repeat that article, but please read through yourselves. It covers the following areas:
- What’s the intended audience for the medallion architecture
- The role of OneLake
- Lakehouse Table & File areas
- Basic overview of the Delta format (ACID etc.)
- The “standard” Medallion architecture layers (Bronze, Silver, Gold)
- Patterns to setup the Fabric Workspace and Lakehouses
Microsoft recommends creating a Lakehouse in separate Workspaces for each zone
In the Microsoft article, it states that the recommended approach is to create separate Workspaces for each zones (bronze, silver, gold) with a Lakehouse in each (or a Warehouse for the Gold zone).
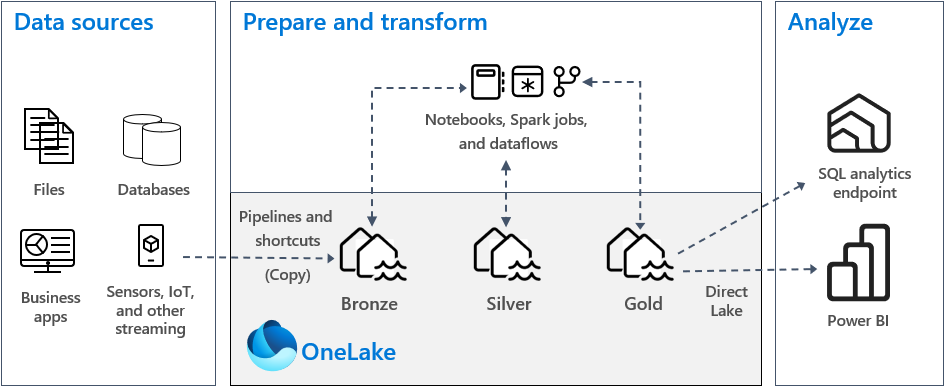
Here’s an image you’ve probably seen if you’ve been reading through MS documentation and community blogs. This is fine…I can see what the items are and a simple flow from left to right, but what I’m after is how I go about engineering this. There are a couple of thing I’ve noted about this diagram:
- Data Pipelines are listed as the source data loading process from source systems in to the Bronze/Raw layer only. Which does make sense as pipelines are not really for data transformation, rather for bulk loading from a variety of data sources into Fabric itself.
- Notebooks and Dataflow Gen2 are listed here as the data transformation tools, again yes this makes sense as these are the tools you can use to take data and transform it into what you need.
So that’s the “descriptive” article by Microsoft on the Medallion architecture, but there’s also the Learn article Organize a Fabric lakehouse using medallion architecture design in which it actually takes you through an exercise in building a simple architecture. However, taking a look through the module, the learning path shows how to create a single Lakehouse and then create separate bronze, silver, and gold tables. Useful to get started yes, but it’s not what the recommended layout is… all the tables are in the same Lakehouse in the same workspace.
What now? Well, let’s take a look at the various options we have in Fabric for loading data, this includes loading data between Lakehouses in different Workspaces, as there some things to note.
Fabric Loading
So how do we go about actually implementing this architecture in Fabric when using Microsoft’s recommended approach of using multiple Workspaces for the medallion zones? We can just create Data Pipelines, Dataflow Gen2, and Notebooks to start loading data between these zones…easy! Well, yes but there are caveats. Let’s take a look, however there are a few permutations of what is possible so please bear with me, I’ve attempted to outline as I see it.
Data Loading and Transformation Options
Firstly, let’s cover Shortcuts as this is very useful way to query Lakehouse data from other Lakehouses in either the same or a different Workspace. We can create Shortcuts in a Lakehouse to load data from another Lakehouse. E.G. create a shortcut in the Silver Lakehouse to tables in a Bronze Lakehouse.
Shortcuts
- Easy to setup via Fabric UI but is a manual process, no API (this is coming though)
- Query a Lakehouse (or Warehouse) in the same or different Workspace
- Query data that sits outside Fabric, E.G. Azure Data Lake Gen2, AWS S3
- Notebooks can reference Shortcuts as a source
- Data Pipelines can reference Shortcuts as a source
- Dataflow Gen2 can reference Shortcuts as a source
- Cannot create shortcuts from Warehouses to other resources
Now let’s look at the data loading & transformation options within native Fabric (I won’t cover Databricks/Synapse Analytics Notebooks here). Also, in terms of Data Pipelines, I’m looking specifically at the Copy Data task. Data Pipelines can be used to schedule Copy Data tasks, plus Dataflow Gen2 and Notebooks too.
Feel free to reach out to me and discuss any of the below info, I may have missed a particular scenario or possibility so please let me know.
Data Pipelines – Copy Data Task
The Copy Data task is great for moving/copying data around different data stores, however it’s not particular nuanced in terms of transformation – there’s not a great deal you can do with the data you’re moving. Any transformation would probably happen in the query you use as the source, E.G. data transformation in a SQL query.
- Allows loading of data to/from Lakehouse/KQL Database/Warehouse
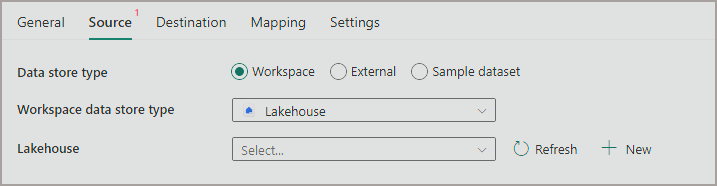
- Can’t reference any Lakehouse/KQL Database/Warehouse in another Workspace when using the Workspace data store type.
- Can’t reference OneLake directly using External option and specifying a OneLake URL. There’s an error stating ” The domain of this endpoint is not in allow list. Original endpoint: ‘onelake.dfs.fabric.microsoft.com”
- Can reference Shortcuts in the same workspace Lakehouse (which allows loading from a lakehouse in a different Workspace) as a source only. You can’t use a Shortcut as a destination.
Dataflow Gen2
Dataflow Gen2 allows you to load data to/from destinations and also transform data using both the UI options and the M language. Anyone familiar with Power Query in Power BI and Data Flows in Power BI Service will recognise it. I hesitate to say this is the “no code/low code” option as you can use plenty of M language here, but you can design your data transformation using the UI.
- Can connect to many different sources including Lakehouse, Warehouse, Azure Data Lake, Azure SQL Database, Sharepoint, Web API etc
- Can connect to a different Workspace Lakehouse/Warehouse with both source and also destination
- Can load into destinations Lakehouse, Warehouse, Azure SQL Database, Azure Data Explorer
- Can overwrite or append data in a destination
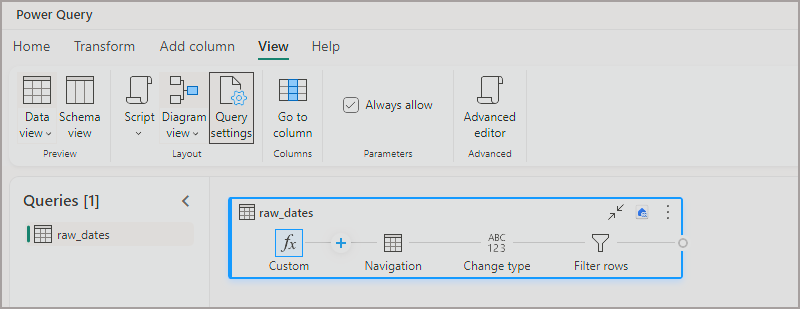
In the following image I have connected to a Lakehouse Table in the Bronze (Raw) Workspace, added a series of data transformation steps, then configured the destination to be a Lakehouse in the Silver (Cleansed) Workspace. The Dataflow Gen2 exists in the Silver Workspace.
Notebooks
In Notebooks we can write code (PySpark, Scala, Spark SQL, R) to load, transform, and write data to a variety of sources/destinations. There are custom libraries available to connect to a wide variety of services, but I’ll concentrate on Lakehouses here.
I can see plenty of data loading and processing frameworks being created and made available using Notebooks, after all it’s pure code…and that’s extremely flexible.
- Can work with Lakehouse Tables and Files using 2 part naming convention (no requirement to use a schema in the name) in a Notebook with Lakehouses in the same Workspace.
- Can’t load/write to a Lakehouse using any part naming convention in a different Workspace even if it’s attached to a Notebook, you’ll get an error saying the object can’t be found as there’s no cross-workspace querying available
- Can use full paths to work with Lakehouse Tables and Files in different Workspaces
Here’s an example of selecting from different Lakehouses in the same Workspace:
df = spark.sql("SELECT * FROM LH_RAW_WEBTELEMETRY.webtelemetryanalysis LIMIT 1000")
display(df)
df = spark.sql("SELECT * FROM LH_CLEANSED_WEBTELEMETRY.webtelemetryanalysis LIMIT 1000")
display(df)
Here’s an example of using a full URL in PySpark in a Notebook to access a Delta table stored in a Lakehouse in a different Workspace.
df = spark.read.format("delta").load("abfss://workspacename@onelake.dfs.fabric.microsoft.com/LakehouseName.Lakehouse/Tables/Product")
df.show(5)
SQL
And of course there is SQL! With SQL we can do the following:
- Can query a Lakehouse SQL Endpoint in read-only mode, however we can only query a Lakehouse SQL Endpoint in the same Workspace. We can’t query a SQL Endpoint from another Workspace. E.G. we can’t run a SELECT from one Lakehouse which references another Lakehouse in another workspace as cross-workspace querying is not allowed.
- Can query Shortcuts in a Lakehouse SQL Endpoint that point to another Lakehouse.
- Can query (and load) a Warehouse by querying a Lakehouse (or another Warehouse) in the same Workspace using 3 part naming convention
- Can load a Warehouse using SQL. E.G. have SQL loading logic within Warehouse Stored Procedures.
In the following example, we can INSERT into a Warehouse from a Lakehouse in the same Workspace by running this SQL against the Warehouse which will query the Lakehouse SQL Endpoint. We can also do the same but using a Shortcut in the Lakehouse that points to another Workspace Lakehouse. However, in both examples there must be a Lakehouse in the same Workspace as the Warehouse.
--load a Warehouse table from a lakehouse in the same Workspace INSERT INTO dbo.warehousetable SELECT <column_list> FROM Lakehouse.dbo.TableName; --load a Warehouse table from a lakehouse in the same Workspace INSERT INTO dbo.warehousetable SELECT <column_list> FROM Lakehouse.dbo.ShortcutTableName;
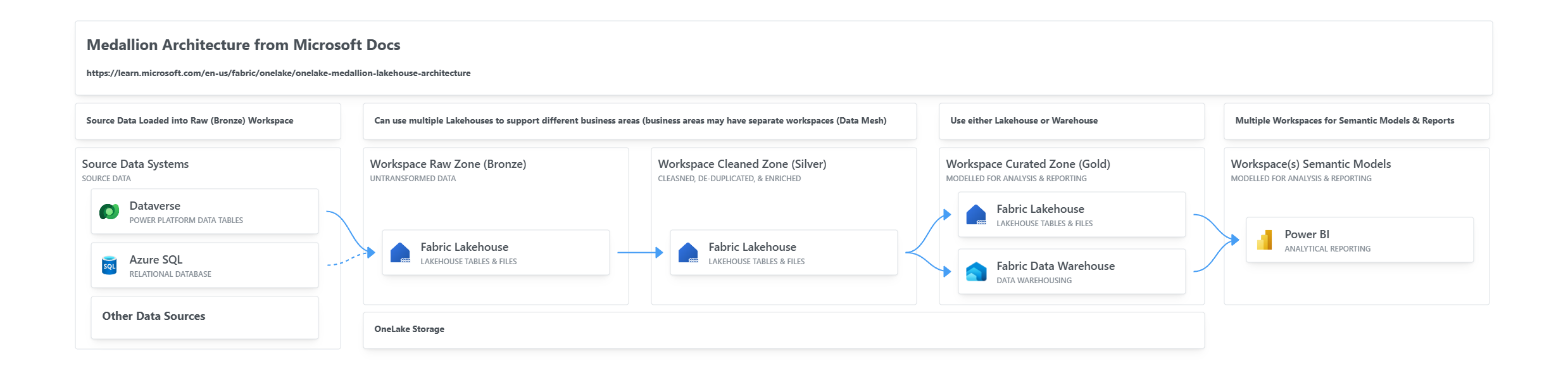
Part 2 Peek: Separate Workspaces for Each Zone
In Part 2 I’ll go into what I’ve been doing to develop a basic solution using Lakehouses in different Workspaces. This is the approach that Microsoft recommends, and it does make sense overall. I think of workspaces like individual servers (each workspace has it’s own endpoint for connecting to a Lakehouse or Warehouse SQL Endpoint, plus an XMLA endpoint) so for me, splitting the bronze/silver/gold zones across these “separate” workspaces makes sense.
Basic Architecture Overview
I tend to use Azure Diagrams to get a quick diagram together, I recommend checking it out here. It’s created by Microsoft employees and although not technically a Microsoft product, it’s very handy for the community.
Link to the Azure Diagram is below (link to Azure Diagrams). You can create an account/login and clone it.
Conclusion
In Part 1 we’ve taken a look at the resources Microsoft have created in terms of implementing a Medallion Architecture pattern in Fabric, but that was only a part of the overall story. It’s recommended that we setup different Workspaces in Fabric and organise the relevant Lakehouse/Warehouse(s) in these Workspaces but how do we load data between the Workspaces? We then had a look through the data loading processes available in Fabric and outlines pros/cons of each.
In Part 2 we’ll take all of the above info and start to create a solution in Fabric using the relevant data loading processes.
References
- Implement medallion lakehouse architecture in Microsoft Fabric – Microsoft Fabric | Microsoft Learn
- What is the medallion lakehouse architecture? – Azure Databricks | Microsoft Learn
- Building the Lakehouse Architecture With Azure Synapse Analytics – SQL Of The North
- Behind the Hype – The Medallion Architecture Doesn’t Work – YouTube
- Exploring Fabric OneLake vs Azure Data Lake Gen2 Storage Accounts (serverlesssql.com)
- Azure Diagrams
 Andy
Andy