

A question that is often asked about Azure Synapse Analytics is how it handles Delta tables that are partitioned. Delta tables (or the Delta Lake) is one of the technologies that underpins the Lakehouse architecture (also see Iceberg & Hudi). It’s a storage technology that enables the separation of storage and compute and provides transactional consistency. I’m being very simplistic in my definition of the Delta format here for the sake of brevity, you can read more here.
We’ll be looking at how Synapse deals with partitioned Delta tables in Lake Databases & Serverless SQL Pools databases
To drill down a little more into what this blog post is about, we’re going to look at how Synapse handles partitioned tables in the Delta format when using both Lake Databases and Serverless SQL Pools databases. Now…a word of warning.
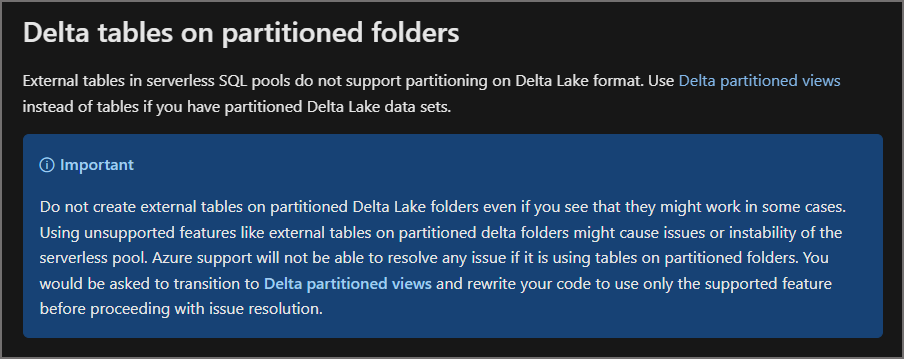
Delta Tables in Serverless SQL Pools Warning
I get questions about Delta tables in Serverless SQL Pools databases frequently and unfortunately they are only partially supported (hence the confusion). Although you can create Delta tables in Serverless SQL Pools over both non-partitioned and partitioned folders, only non-partitioned is supported. But we’ll see in this blog that you can create a Delta table over a partitioned folder…and get undesirable results. Documentation here.
TLDR
I show that when creating external Delta partitioned tables in Spark, the table definition is syncronised to Serverless SQL Pools and partition elimination works fine when querying using Serverless SQL Pools. If you create an external Delta partitioned table directly in a Serverless SQL Pools database, the partitioning does not work although data can be selected, which is dangerous because all data is scanned and this will add to your Azure bill!
Database Types
We have 2 types of SQL databases that can be used to cast structure over and work with data in the data lake, Lake Databases, and Serverless SQL Pools databases. I’ll be honest, I’m not a fan of having multiple database types…why can’t it just be a single database type? Well, it’s to do with the technology that underpins each database type.
- Serverless SQL Pools Database: Uses the Polaris engine created at Microsoft, language is SQL
- Lake Database: Uses the Spark engine with language support for Scala, Python, SQL etc
Metadata Syncronisation
I won’t go into too much detail here in terms of the metadata syncronisation feature within Synapse (more here), but it’s important to cover it here briefly. This is a one-way process in which external tables created within a Lake Database are made available to the Serverless SQL Pools service. The upshot is you can work with tables in a Lake Database using Spark, e.g. data engineering processes to insert/update/delete data in the data lake, modify schema information etc., but then actually use Serverless SQL Pools to query the data using the external tables. It’s becoming a popular method as the pricing model for Serverless SQL Pools is based on the amount of data processed, and nothing to do with any cluster size or up-time. E.G load Power BI data models from Serverless and only pay for the data that is read (processed) without having to worry about switching Spark clusters on/off.
Partitioned Delta Tables
Let’s jump into the issue here, we can work with Delta tables in both Lake Databases and Serverless SQL Pools databases. However, there is some missing functionality at the moment that is causing some confusion about what is/isn’t working. While it’s technically possible to create Delta tables in Serverless SQL Pools, they don’t work as expected. This is actually called out in the Microsoft documentation.
In the simple diagram below we see a data processing engine targeting a specific folder in the data lake, that is partition pruning.

Here are the relevant scenarios when creating external tables over partitioned Delta data.
| Scenario | Outcome |
|---|---|
| External Delta partitioned table created in Lake Database | Can query including partition pruning |
| External Delta partitioned table created in Serverless SQL Pools database | Can query but partitioned columns are NULL therefore partitioning does not work |
| External Delta partitioned table created in Lake Database and automatically syncronised to Serverless SQL Pools | Can query In serverless SQL Pools including partition pruning |
Why do we care about partitioning?
In short, we care about partitioning because it can improve read and write performance and in the case of Serverless SQL Pools, reduce cost, as only the relevant partitions (folders) are scanned when retrieving data. There’s cost associated with running Spark clusters too, so if you can run smaller clusters for shorter periods of time, then all good.
Also, partitioning isn’t always a good option as the benefits of separating the data into folders may actually cause degradation in performance as the data processing engine needs to traverse folders and scan/read individual files. As always, plan ahead in terms of partitioning.
Walkthrough
Let’s go through the partitioning scenarios above and do the following:
- Create a Lake Database external table over partitioned Delta data and query
- Create a Serverless SQL Pools external table over partitioned Delta data and query
- Create a Lake Database external table over partitioned Delta data and query using Serverless SQL Pools
Checking for Partition Pruning
I’ll be using Log Analytics to check what folders are being scanned in the Azure storage account when running queries. There is a blog here detailing how to set this up.
Create Lake Database External Table
We’ll be creating a Delta table with the following schema:
- UserID
- EventType
- ProductID
- URL
- Device
- SessionViewSeconds
- EventDataNoPart (data column not in partition scheme)
- EventYear (partition column)
- EventMonth (partition column)
- EventDate (partition column)
The code below is running in a Synapse Notebook connected to a Spark pool. I have already loaded a dataframe called dftwo source data, then we can then run the following code which saves the dataframe to a data lake folder in the Delta format. Then we run a SQL query to create a table over the Delta data, and finally we run a SELECT on the Delta table.
%%pyspark
dftwo.filter("EventDate IS NOT NULL").write.format("delta").partitionBy("EventYear", "EventMonth", "EventDate").save("abfss://container@datalakestorage.dfs.core.windows.net/cleansed/webtelemetrydelta")
%%sql CREATE DATABASE SparkDelta; CREATE TABLE IF NOT EXISTS SparkDelta.webtelemetrydelta USING DELTA LOCATION 'abfss://datalakehouseuk@dhstordatalakeuk.dfs.core.windows.net/cleansed/webtelemetrydelta';
%%sql
SELECT
EventType,
COUNT(*) AS TotalEventCount
FROM SparkDelta.webtelemetrydelta
WHERE EventDate = '2022-02-20'
GROUP BY
EventType
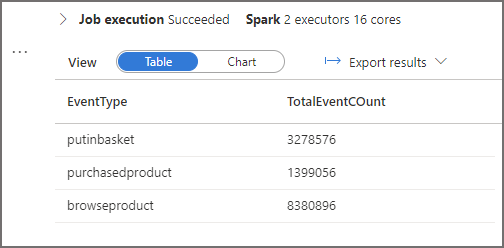
In the results (image to the right) we can see an aggregated total for the events for February 20th 2022. We can now analyse Log Analytics to see what folders in the Data Lake were scanned when the query was run via the Spark pool.
We are expecting to see just the \EventYear=2022\EventMonth=02\EventDate=2022-02-20\ folder being scanned to retrieve the results.
Check Log Analytics
We can now check Log Analytics to see which folder(s) were scanned during the running of the query above. The following KQL (Kusto Query Language) query will select all the read events from the Azure storage account that targeted the root folder. This will then show all partition folders that were scanned. It’s a basic query, I’m still finding my way around the KQL language.
StorageBlobLogs
| where TimeGenerated between (datetime(2023-01-29 12:00:00) .. datetime(2023-01-30 21:00:00))
and ObjectKey contains "/dhstordatalakeuk/datalakehouseuk/cleansed/webtelemetrydelta"
and OperationName == "ReadFile"
| summarize count() by TimeGenerated,replace_string(ObjectKey,'/dhstordatalakeuk/datalakehouseuk/cleansed/webtelemetrydelta','')
| sort by TimeGenerated desc

The results show that only the /EventDate/2022-02-20 folder was scanned therefore successful partition elimination.
Create Serverless SQL Pools External Table
We’ll create the external table over the same Delta location from the previous scenario. The code below is run on Serverless SQL Pools and creates a new database, security to allow connection to the data lake, then creates the external table over the Delta folder.
--create new Serverless SQL Pools database
CREATE DATABASE SQLDelta;
--Switch to the new database
USE SQLDelta;
--Create a schema to hold our objects
CREATE SCHEMA LDW authorization dbo;
--encryption to allow authentication
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<complex_password>';
--Create a credential using Managed Identity
CREATE DATABASE SCOPED CREDENTIAL DataLakeManagedIdentity
WITH IDENTITY='Managed Identity'
--Create a data source for use in queries
CREATE EXTERNAL DATA SOURCE ExternalDataSourceDataLakeUKMI
WITH (
LOCATION = 'https://<datalake>.dfs.core.windows.net/datalakehouseuk',
CREDENTIAL = DataLakeManagedIdentity
);
--create delta file format
CREATE EXTERNAL FILE FORMAT DeltaFormat
WITH
(
FORMAT_TYPE = DELTA
)
--create external table
CREATE EXTERNAL TABLE WebTelemetryDelta
(
UserID varchar(20),
EventType varchar(100),
ProductID varchar(100),
URL varchar(100),
Device varchar(50),
SessionViewSeconds int,
EventDateNoPart date,
EventYear int,
EventMonth int,
EventDate date
)
WITH (
LOCATION = 'cleansed/webtelemetrydelta',
DATA_SOURCE = ExternalDataSourceDataLakeUKMI,
FILE_FORMAT = DeltaFormat
)
GO
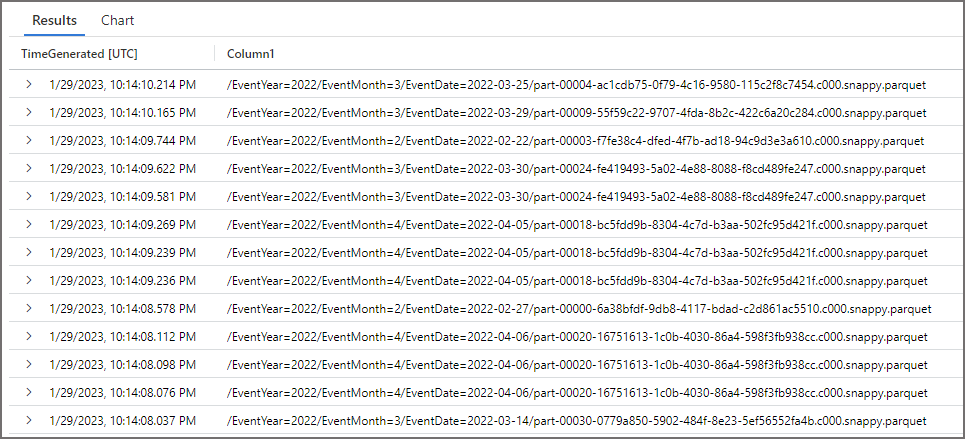
Although the above SQL is technically possible and we don’t get any errors when running it, when we try and query the external table using Serverless SQL Pools, we don’t get any results back.
SELECT
EventType,
COUNT(*) AS TotalEventCount
FROM WebTelemetryDelta
WHERE EventDate = '2022-02-20'
GROUP BY
EventType
As you can see, we get no results back from the SQL query above.
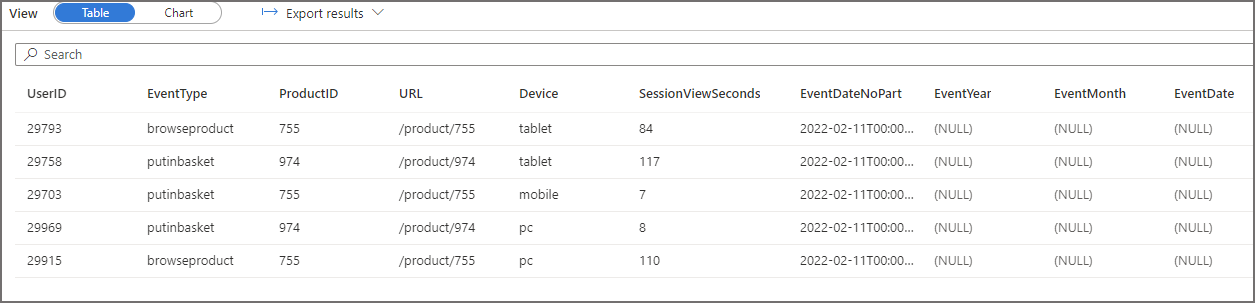
If we run a SELECT to return all the column values then we can see the partition columns all return as NULL. So although we can query the table and it does actually return the table values, it doesn’t recognise/parse the partition columns…
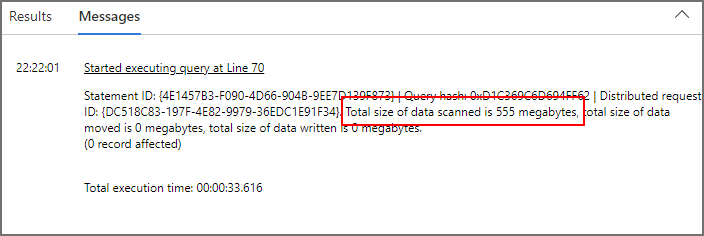
What we also see in Log Analytics is that all the folders in the Delta root were scanned, this could be potentially dangerous as the entire Delta folder would be scanned and be charged!
Create Lake Database External Table and query with Serverless SQL Pools
Now let’s create another external table (we could use the existing table created in the first scenario but let’s keep it separate). First we’ll load a new folder with the partitioned Delta data, then we’ll create an external table over the Delta folder. We should then be able to use this external table in Serverless SQL Pools. It usually takes a few seconds for the metadata to sync and be visible to Serverless SQL Pools but sometimes I’ve waited for a couple of minutes.
You can check if an external table created in a Spark pool has been successfully synced by querying the sys.external_tables system table in the Serverless SQL Pools database and checking that the table exists.
%%pyspark
dftwo.filter("EventDate IS NOT NULL").write.format("delta").partitionBy("EventYear", "EventMonth", "EventDate").save("abfss://container@datalakestorage.dfs.core.windows.net/cleansed/webtelemetrydeltatwo")
%%sql CREATE TABLE IF NOT EXISTS SparkDelta.webtelemetrydeltatwo USING DELTA LOCATION 'abfss://datalakehouseuk@dhstordatalakeuk.dfs.core.windows.net/cleansed/webtelemetrydeltatwo';
We now run the following SQL in Serverless SQL Pools.
SELECT
EventType,
COUNT(*) AS TotalEventCount
FROM webtelemetrydeltatwo
WHERE EventDate = '2022-02-20'
GROUP BY
EventType
Check Log Analytics
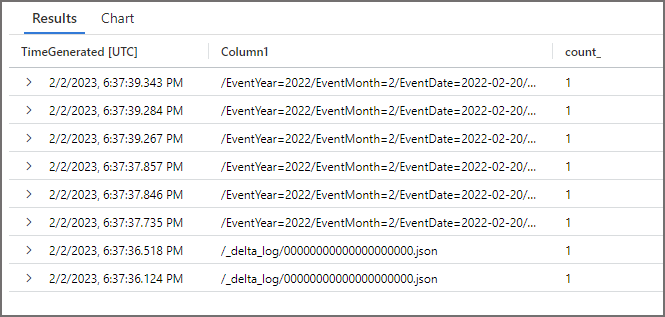
We can see that only the EventYear/EventMonth=2/EventDate=2022-02-20 folder was scanned.
Alternatives in Serverless SQL Pools for Delta
We can create a View in a Serverless SQL Pools database over a Delta folder in the Data Lake, this respects the partition scheme and the partition columns work fine and return values.
CREATE VIEW LDW.vwWebTelemetryDelta
AS
SELECT
UserID,
EventType,
ProductID,
[URL] AS ProductURL,
Device,
SessionViewSeconds,
EventYear,
EventMonth,
EventDate
FROM
OPENROWSET
(
BULK 'cleansed/webtelemetrydeltatwo',
DATA_SOURCE = 'ExternalDataSourceDataLakeUKMI',
FORMAT = 'DELTA'
)
WITH
(
UserID INT,
EventType VARCHAR(20),
ProductID SMALLINT,
URL VARCHAR(25),
Device VARCHAR(10),
SessionViewSeconds INT,
EventYear SMALLINT,
EventMonth TINYINT,
EventDate DATE
) AS fct
We can then run an aggregate query with a filter and the partition scheme is recognised and respected.
SELECT
EventType,
COUNT(*) AS TotalEventCount
FROM LDW.vwWebTelemetryDelta
WHERE EventDate = '2022-02-20'
GROUP BY
EventType
Conclusion
In this blog post we’ve looked at what happens when we create external Delta partitioned tables in both Spark pools and Serverless SQL Pools and the behaviour both expected and un-expected.
References
- Query Delta Lake format using serverless SQL pool – Azure Synapse Analytics | Microsoft Learn
- Create and use views in serverless SQL pool – Azure Synapse Analytics | Microsoft Learn
- Create and use external tables in Synapse SQL pool – Azure Synapse Analytics | Microsoft Learn
- Kusto Query Language (KQL) overview- Azure Data Explorer | Microsoft Learn
 Andy
Andy