

Welcome to this new blog series in which I’ll be diving into both Power BI and Azure Synapse Analytics features that can work together. These features are not exclusive between Synapse and Power BI though, they are simply features that enhance the experience between these platforms. E.G. as ResultSet Caching is a Synapse Dedicated SQL Pools feature, any SQL client that sends a SQL request to the Dedicated SQL Pool can benefit from this feature.
What is ResultSet Caching?
ResultSet Caching is a Dedicated SQL Pools feature which caches a dataset created using a SELECT query, for example a query that aggregates data, or returns all the data from a table (e.g. in a Power BI table load). If the query satisfies certain criteria (listed below) then it gets added to the Dedicated SQL Pools cache. Then when a request comes in that matches the query definition then the result can be served from the cache. This is really beneficial for a couple of reasons:
- It speeds up the retrieval of the result as it can just return from the cache
- It also does not use up any resource allocation % for the Dedicated SQL Pool.
Each user querying Dedicated can be assigned to a resource class, this resource class is allocated a certain % of system resources. E.G. if a user assigned to the smallrc resource class runs a single SQL query, and the Dedicated SQL Pool is set to DWU200c (120GB RAM), that query is assigned 12.5% of the total system resources, which would be 9.6GB RAM (more info here).
Criteria
There are a few criteria a query must meet before it can be added to the ResultSet Cache:
- ResultSet Caching must be enabled on the Dedicated SQL Pool database
- No data changes in the table
- No schema changes in the table
- Queries using user-defined functions are non-deterministic functions like GetDate()
- Dedicated SQL Pool tables with Row-Level Security
- Queries which return a dataset larger than 10GB
- Queries with row sizes larger that 64K…that is roughly 16 VARCHAR(4000) columns 😉
All the criteria is available here.
So why is it useful with Power BI?
So why do we care about ResultSet Caching in Power BI? Well, if we’re loading data from Dedicated SQL Pools and if that data hasn’t changed then it’ll be delivered from the cache. This means it won’t take up any Dedicated SQL Pools resources and will load faster.
In the diagram below we have 4 tables in Power BI that are loaded on each scheduled/on-demand refresh. 2 of those tables can be satisfied from the cache and the other 2 are allocated resources according to the user that Power BI is configured to access Dedicated with.
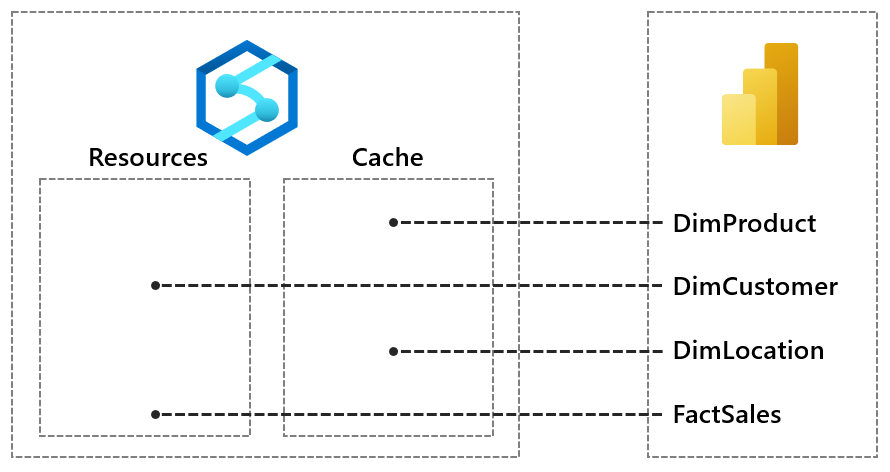
The criteria which enables ResultSet Caching is important here, because often when loading data from database systems, it’s recommended to use views rather than referencing the table directly. Now sometimes those views might contain certain functions which are non-deterministic like GetDate()…if we can avoid these then we should be able to use the cache.
Testing ResultSet Caching
Let’s test now and see the impact when loading a Power BI Dataset with a set of dimension and fact tables. We’ll first ensure the feature is switched off as we’ll see the impact when off and on. For this test I’ll be running the Dedicated SQL Pool at DWU200c (120GB) RAM and the user setup to load from Power BI is assigned to the smallrc resource class. The minimum % granted to a query for this user at DWU200c will be 12.5% (so we can run 8 concurrent queries across the whole system).
--run on the master database ALTER DATABASE dhdatawarehouseuk SET RESULT_SET_CACHING OFF --check caching SELECT name, is_result_set_caching_on FROM sys.databases WHERE name = 'dhdatawarehouseuk';
Here’s the Power BI dataset we’re working with, 6 tables in total. And yes the Fact table is pretty small, 1M rows (just for testing of course!). What we’ll do is refresh this dataset with caching switched off then on and we’ll see the impact.
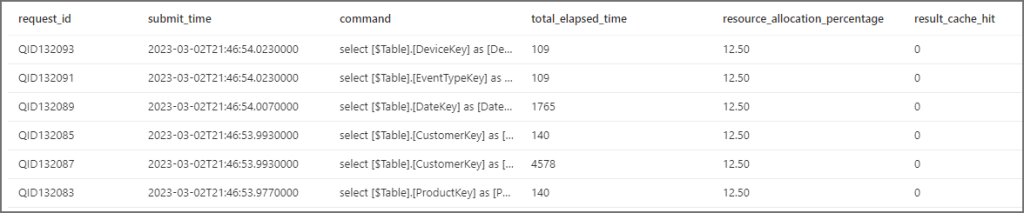
After hitting refresh on the dataset to reload the tables, then querying the Dedicated SQL Pool using the super-useful sys.dm_pdw_exec_requests DMV we can see the following. NB: the command like ‘%DW%’ filter is just to select the queries that are loading from the DW tables for the Power BI dataset.
--check requests
SELECT
request_id,
submit_time,
command,
total_elapsed_time,
resource_allocation_percentage,
result_cache_hit
FROM sys.dm_pdw_exec_requests
WHERE command LIKE '%DW%'
AND session_id != SESSION_ID()
ORDER BY submit_time DESC;
What we can see in the results below is that we had 6 queries hitting the Dedicated SQL Pool and all queries were allocated 12.5% if the total system resources. Also notice that the result_cache_hit column shows -1 which means the cache was not enabled (all result values are here).

Let’s now enable the cache on the Dedicated SQL Pool and run the Power BI dataset refresh again.
--run on the master database ALTER DATABASE dhdatawarehouseuk SET RESULT_SET_CACHING ON --check caching SELECT name, is_result_set_caching_on FROM sys.databases WHERE name = 'dhdatawarehouseuk';
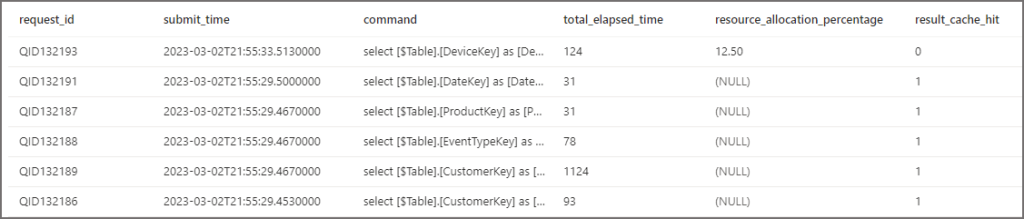
If we query sys.dm_pdw_exec_requests DMV now (using the check requests SQL query earlier in the blog) we can see that we have the same 12.5% resource allocations taking place for each query being run. But we also have slightly longer query times which includes the overhead of populating the cache for the first time. Notice that we have 0 for the result_cache_hit which means the query was not served from the cache but no specific error (all errors are negative numbers).
So it’s back to Power BI again to run the dataset refresh once more… Now if we query the sys.dm_pdw_exec_requests DMV we can see that each query is no longer using any of the Dedicated SQL Pool system resources, we have NULL for the resource_allocation_percentage. This means that these queries are not contributing to any concurrency allocation. We also have the value 1 in result_set_cache which means the query was served from the cache.

Let’s just do one final thing…bear with me…. Let’s run a query to insert new data into the Fact table. If we run this query it should invalidate the cache
--invalidate cache for a table INSERT INTO DW.DimDevice VALUES (4,'Console')
Now we can see that as the DimDevice table data has changed (new row added), the cache has been invalidated for the query that selects from this table. The system has allocated resources again for the query that selects from the table, and the time taken also includes loading the cache again.
Why switch caching off though?
Well, you could leave it enabled all the time – certainly on the Dedicated SQL Pools database level but then turn it off on a per session basis. Think about workloads where caching isn’t particularly useful like ETL/ELT operations or adhoc exploratory queries – these could use up the total cache limit (1TB) for no real benefit and there’s a slight overhead when populating the cache for the first time when running a query. Again, it’s all about the usage patterns in the Dedicated SQL Pool.
Thoughts
I’m all about the options though and as an alternative we can also set-up individual partition/table refreshes on the Power BI side using the Power BI XMLA endpoint, that would require knowing what has/hasn’t been updated and triggering the required table update.
Also, if we are worried about flooding the Dedicated SQL Pool with too many concurrent query requests from Power BI, we also have the option of setting parallel loads off in the Power BI Desktop workbook. These settings are then respected when deploying to the service.
References
- Resource classes for workload management – Azure Synapse Analytics | Microsoft Learn
- Performance tuning with result set caching – Azure Synapse Analytics | Microsoft Learn
- sys.dm_pdw_exec_requests (Transact-SQL) – SQL Server | Microsoft Learn
 Andy
Andy