

Welcome to part 2 in the Synapse Link for Dataverse Delta Lake series. In the recently released functionality in Synapse Link for Dataverse to export to Delta Lake format, this involves creating and running Spark pools in a Synapse workspace. But when do these Spark pools run and can we control when they run? Spark pools are a chargeable service so ideally we want to be able to budget for this and work out when the pools run (and for how long).
In this part we’re going to be looking at how to configure the time interval that the Spark compute will run to merge the exported Dataverse CSVs into the relevant Delta Lake folders.
Part 1 in the series shows how to setup the Delta Lake exporting.
Setting up Time Intervals for Delta Merge
To dictate when the Synapse Spark pools start up and write the Dataverse exported CSV data to the Delta Lake folders, use the Time interval (in minutes) setting in the Power Apps portal when setting up the Synapse Link and selecting tables. Please note that once this setting is configured, it can’t be changed and is global across all the tables (so you can’t pick and choose the time interval for each table).
If you need to change the time interval you’ll need to Unlink the Synapse Link and start again.
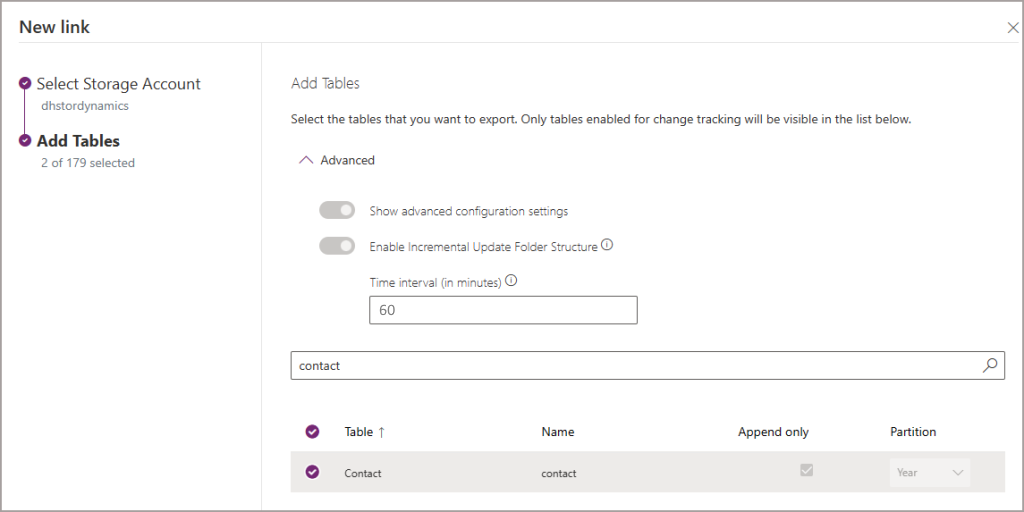
Monitoring Spark Applications to Check Spark Pools
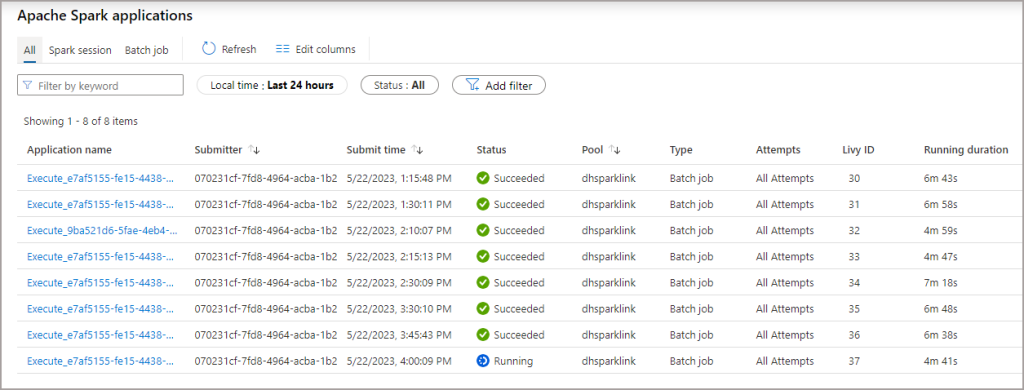
Once the Synapse Link has been configured, we’ll start to see Spark batch job activity in Synapse Studio under Monitoring > Apache Spark Applications. Use the filters to select the Pool that was configured in Power Apps if there are a lot of logs.
The example below shows what happens when the Time interval is set to 15 minutes. If data is changed in Dynamics/Dataverse then that data with be exported to CSV and the Spark batch job will run the merge into the Delta Lake.
Please note that if no data is changed in Dynamics then the Spark jobs are not run, so don’t worry about Spark running when it doesn’t need to. You will also see a single daily batch job that runs for doing Delta maintenance, and that will happen every day regardless if any data has changed/exported from Dynamics/Dataverse.
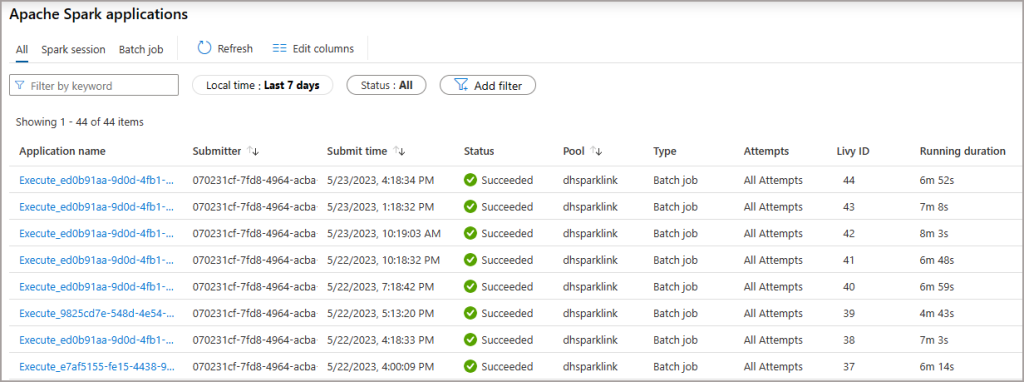
If we choose a 3 hour (180) minute time interval then when data changes are made in Dynamics/Dataverse the data is merged into the Delta Lake on that schedule. In the image below we can see 3 hours intervals between the batch jobs (there are a couple of other jobs as well as I added more tables to the sync process).
Although the Delta Lake merge process only happens as per the Synapse Link time interval, the data is actually exported to CSV in “near real-time.” This CSV data isn’t accessible via the Lake Database so you still need to wait until the Spark batch job is run for the CSV data to be merged into the relevant Delta Lake tables. Then you can query the relevant tables using Serverless SQL Pools or Spark pools.
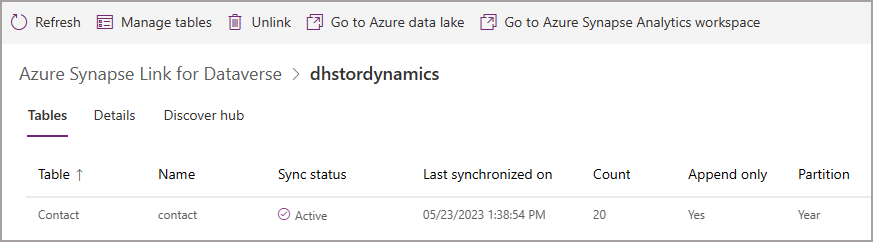
The CSV data is exported from Dynamics/Dataverse in near real-time, but is only merged into Delta Lake as per the time interval in the Synapse Link.
Conclusion
In this blog we’ve looked at how to configure the frequency in which the Spark pools will start and merge the exported CSV data into Delta Lake, this allows you to control when the Spark jobs run and help manage costs.
In the next part we’ll be looking at the metadata that is exported alongside the dataverse tables and how we can use this metadata, so stay tuned!
References
- Export Microsoft Dataverse data in Delta Lake format – Power Apps | Microsoft Learn
- Synapse Link for Dataverse: Exporting to Delta Lake – Serverless SQL
 Andy
Andy