

Overview
Probably one of the most hotly anticipated services is available within Fabric now, as Copilot in Fabric is now in public preview. See the official blog here for more details. I’ve been quietly interested in what Copilot can bring to Fabric and get hands-on with it to see if this AI-driven revolution is as great as the marketing would have you believe.
In this blog I’m going to pick the Data Engineering Copilot feature, which allows you to ask Copilot for help when coding data loading, processing, and transformations in a Fabric Notebook. I know enough Python & PySpark to get by, and certainly would welcome a helping hand when coding data solutions.
I wondered how useful Copilot would be to me when trying to process data in a Lakehouse table, clean it, and save it to another table. In this blog I’m going to list down all the prompts I gave Copilot and the results I got back.
Enabling & Using Copilot in Fabric
Firstly, you’ll need to enable Copilot in your Fabric environment:
- Open Fabric settings from the main page and select Admin Portal
- Under the Tenant Settings tab, scroll to the bottom of the page
- Enable Copilot and Azure OpenAI Service (preview). If you need to, only enable the feature for certain users/AD groups.
- If you’re outside of US or France, you’ll need to enable the option Data sent to Azure OpenAI can be processed outside your tenant’s geographic region, compliance boundary, or national cloud instance
Once this is done, you’ll also need to have a supported Fabric Capacity. Unfortunately Trial SKUs are not supported so you’ll need a paid SKU. I’m using an Azure F64 SKU which I have assigned to a Fabric Workspace.
In my basic scenario I have created a new Lakehouse and loaded a small Delta table using the Load To Tables feature. I have then created a new Notebook and can see the Copilot button enabled, so I’m ready to go.
- Click the Copilot button at the top of the Notebook
- In the window that appears to the right, click Get Started
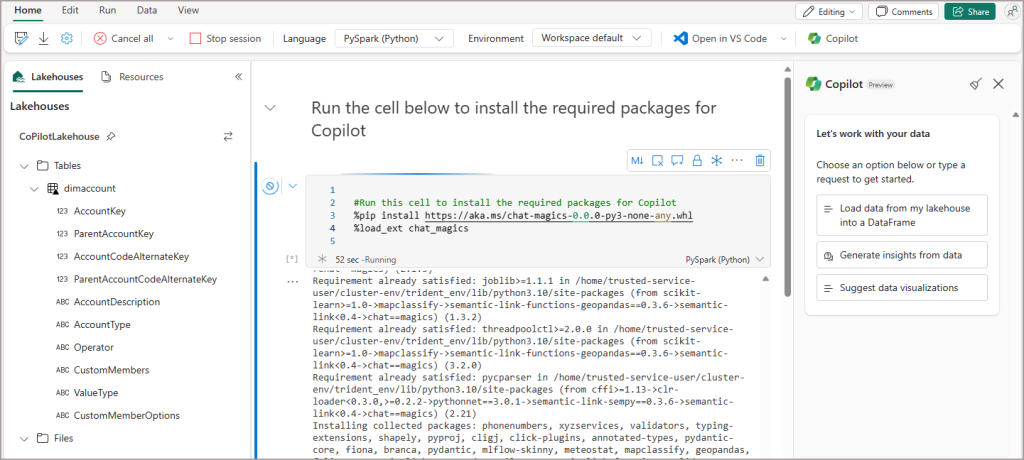
- You’ll see code added to the Notebook to install the Copilot libraries, so go ahead and run the cell.
- This will take a few minutes.
Prompts
We’re ready to go now. The following sub-headings are all the commands/questions I entered into the Copilot prompt. All text in italics is the Copilot description that was returned alongside the actual code.
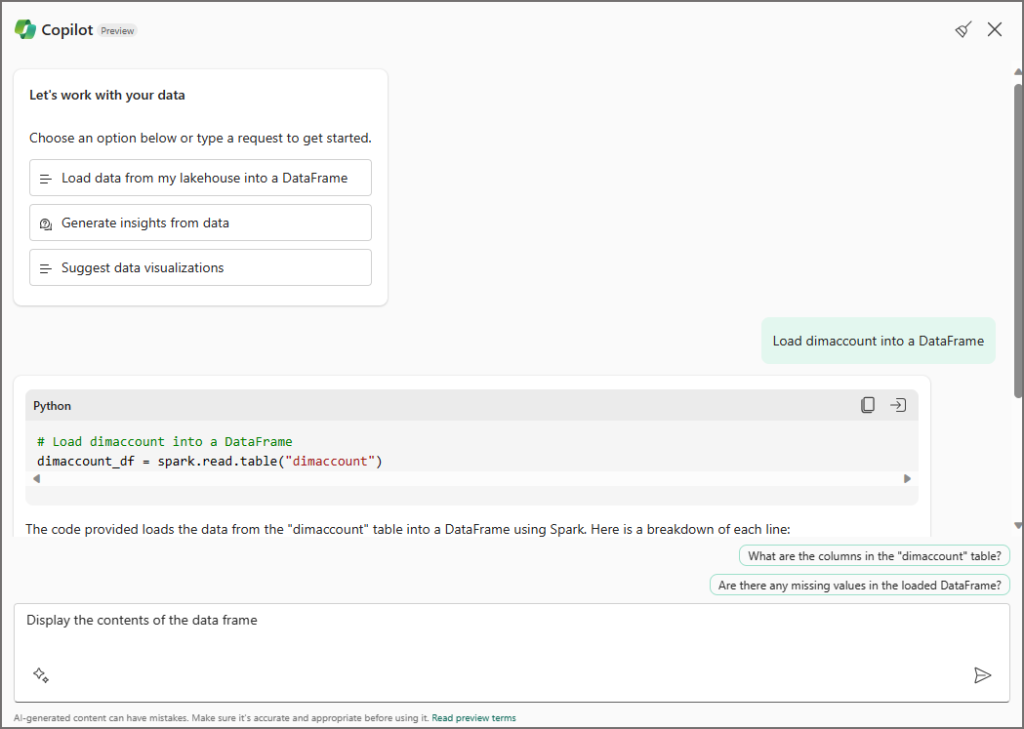
Load dimaccount into a data frame
I actually just clicked the Load data from my Lakehouse into a DataFrame button in the Copilot window and then entered dimaccount as the table I wanted to load.
“You can import data from a table to a dataframe using the following function:
result = spark.sql(f"SELECT * FROM copilotlakehouse.dimaccount LIMIT 1000")
“Comments:
The clause is added to avoid loading too much data into memory.LIMIT 1000
While generating the code, I made the following assumptions:
It’s assumed that the variable name is result.
It’s assumed that the output dataframe type is .”pyspark“
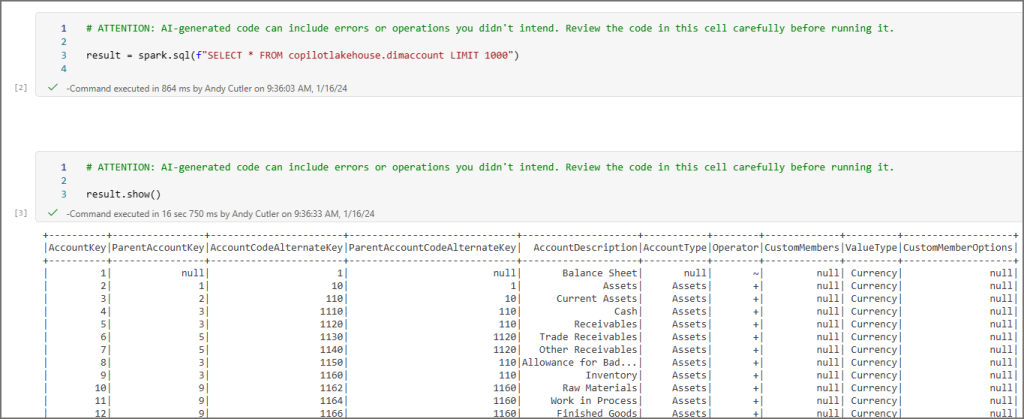
Display the contents of the data frame
“To display the contents of a dataframe in Python, you can use the show() method for Spark dataframes or simply print the dataframe for Pandas dataframes.
Here are the code snippets to display the contents of a dataframe based on the assumed dataframe type:
For Spark Dataframe:
result.show()
For Pandas Dataframe:
print(result)
Choose the appropriate code snippet based on your dataframe type.”
So far so good, I was able to run the code and see the results.
Save the data frame to another table called cleansed_dimaccount
“To save a dataframe to another table called “cleansed_dimaccount”, you can use the saveAsTable() method in Spark. Here’s an example of how to do it:
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it.
# Save the data frame to another table called manual_cleansed_dimaccount
result.write.mode("overwrite").format("delta").saveAsTable("manual_cleansed_dimaccount")
“In this code, df represents your dataframe that you want to save. The write method is used to specify the output format, which in this case is Delta format. The mode("overwrite") ensures that if the table already exists, it will be overwritten. Finally, saveAsTable("cleansed_dimaccount") saves the dataframe as a Delta table with the name “cleansed_dimaccount”.
Make sure you have appropriate write permissions and that the table name is unique and not conflicting with any existing tables in your lakehouse.”
This also worked fine and created a table called manual_cleansed_dimaccount in the Lakehouse. But what I want is to create a looping process rather than “hard code” a single table. Let’s see what Copilot comes up with.
For each table in the lakehouse beginning with “dim”, load into a dataframe and save to a delta table prefixed with “cleansed_”
import os
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Set the file path for the lakehouse tables
lakehouse_path = "lakehouse/default/Tables"
# Get a list of all table names in the lakehouse directory
table_names = spark.catalog.listTables()
table_names = [row.name for row in table_names if row.name.startswith("dim")]
# Loop through each table and process it
for table_name in table_names:
# Read the table into a Spark dataframe
df = spark.read.table(table_name)
# Save the dataframe as a Delta table with prefix "cleansed_"
cleansed_table_name = f"cleansed_{table_name}"
df.write.format("delta").mode("overwrite").saveAsTable(cleansed_table_name)
“In this code, we retrieve a list of all table names in the lakehouse that begin with “dim”. We then loop through each of these tables, load them into a Spark dataframe using spark.read.table(), and save them as Delta tables with the prefix “cleansed_” using df.write.format("delta").mode("overwrite").saveAsTable().
Please note that you may need to adjust the file path (lakehouse/default/Tables) based on your specific lakehouse configuration. Additionally, ensure that you have appropriate write permissions to save Delta tables.”
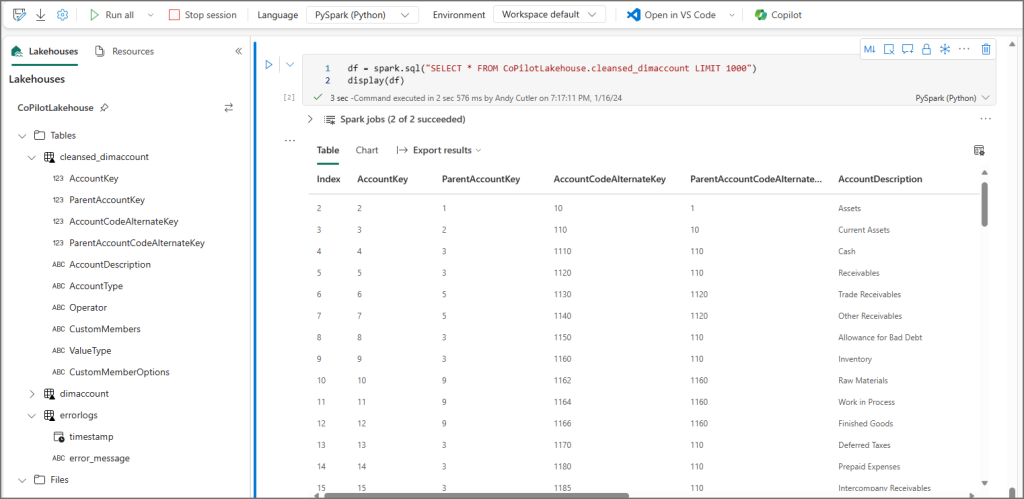
This worked and I could see the new cleansed_dimaccount table in the Lakehouse.
Can you change the logic so that each string column has white space removed?
Now this prompt didn’t amend the previous logic, but rather showed me the process of how to trim columns. I probably need more Prompt Engineering skills here 🙂
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it. # Remove whitespace from string columns in a PySpark DataFrame from pyspark.sql.functions import trim # Apply trim function to each string column df_trimmed = df.select([trim(col).alias(col) if dtype == 'string' else col for col, dtype in df.dtypes]) # Show the updated DataFrame df_trimmed.show()
Let’s just add the trim request into the overall loading process prompt and see what happens.
For each table in the lakehouse beginning with “dim”, load into a dataframe, remove whitespace from all string columns, and save to a delta table prefixed with “cleansed_”
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it.
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import trim
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Set the file path for the lakehouse tables
lakehouse_path = "lakehouse/default/Tables"
# Get a list of all table names in the lakehouse directory starting with "dim"
table_names = [table.name for table in spark.catalog.listTables() if table.name.startswith("dim")]
# Loop through each table and process it
for table_name in table_names:
# Read the table into a Spark dataframe
df = spark.read.table(table_name)
# Remove whitespace from string columns
for col in df.columns:
if df.schema[col].dataType == "string":
df = df.withColumn(col, trim(df[col]))
# Save the cleansed dataframe as a Delta table with prefix "cleansed_"
cleansed_table_name = f"cleansed_{table_name}"
df.write.format("delta").mode("overwrite").saveAsTable(cleansed_table_name)
“In this code, we retrieve a list of all table names in the lakehouse that begin with “dim”. We then loop through each of these tables, load them into a Spark dataframe using spark.read.table(), remove whitespace from string columns using trim(), and save them as Delta tables with the prefix “cleansed_” using df.write.format("delta").mode("overwrite").saveAsTable().
Please note that you may need to adjust the file path (lakehouse/default/Tables) based on your specific lakehouse configuration. Additionally, ensure that you have appropriate write permissions to save Delta tables.”
We now have a step in the process that will remove whitespaces from all string columns in the looping process, I like that! Let’s carry on.
Can you add error handling to the loop?
“Certainly! To add error handling to the loop, you can use a try-except block. Here’s an updated version of the code with error handling:”
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it.
import os
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Set the file path for the lakehouse tables
lakehouse_path = "lakehouse/default/Tables"
# Get a list of all table names in the lakehouse directory starting with "dim"
table_names = [table.name for table in spark.catalog.listTables() if table.name.startswith("dim")]
# Loop through each table and process it with error handling
for table_name in table_names:
try:
# Read the table into a Spark dataframe
df = spark.read.table(table_name)
# Perform any necessary operations on the dataframe
# Save the dataframe as a Delta table with prefix "cleansed_"
cleansed_table_name = f"cleansed_{table_name}"
df.write.format("delta").mode("overwrite").saveAsTable(cleansed_table_name)
except Exception as e:
print(f"Error processing table {table_name}: {str(e)}")
“In this updated code, we have added a try-except block around the processing of each table. If an exception occurs during processing, it will be caught by the except block, and an error message will be printed indicating which specific table encountered an error and providing information about the error itself.
By adding error handling, you can handle exceptions gracefully and provide meaningful feedback when issues arise during processing.”
Did you notice an issue with the code generated by Copilot above? The filter for only selecting tables from the Lakehouse starting with “dim” has been removed, plus there is now no code to trim the string columns and write to a Delta table prefixed with “Cleansed_”… Maybe my prompt engineering skills need some refinement. I’ll carry on asking questions then perhaps ask it to create an overall process.
Can the errors be written to a lakehouse delta table?
We’re still missing the source table filter, the cleansing process, and the load into the destination tables, but it seems to have generated code to insert errors into a Delta table.
“Yes, errors can be written to a lakehouse Delta table. Here’s an example of how you can achieve this:”
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it.
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import current_timestamp
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Set the file path for the lakehouse tables
lakehouse_path = "lakehouse/default/Tables"
# Create an empty dataframe to store error logs
error_logs_df = spark.createDataFrame([], "timestamp:timestamp, error_message:string")
try:
# Get a list of all table names in the lakehouse directory
table_names = spark.catalog.listTables()
table_names = [row.name for row in table_names]
# Loop through each table and process it
for table_name in table_names:
try:
# Read the table into a Spark dataframe
df = spark.read.table(table_name)
# Perform any necessary operations on the dataframe
except Exception as e:
# Log the error message and timestamp to the error logs dataframe
error_logs_df = error_logs_df.union(
spark.createDataFrame([(current_timestamp(), str(e))], "timestamp:timestamp, error_message:string")
)
# Save the error logs dataframe as a Delta table in the lakehouse
error_logs_table_name = "ErrorLogs"
error_logs_df.write.format("delta").mode("append").saveAsTable(error_logs_table_name)
except Exception as e:
print(f"Error retrieving table names: {str(e)}")
“In this code, we create an empty dataframe called error_logs_df with columns for timestamp and error_message. Inside the loop, if an exception occurs while processing a table, we log the current timestamp and error message to error_logs_df. Finally, we save error_logs_df as a Delta table named “ErrorLogs” using write.format("delta").mode("append").saveAsTable(error_logs_table_name).
Ensure that you have appropriate write permissions and that the Delta table name is unique and not conflicting with any existing tables in your lakehouse.”
When I copied this code in and ran it, I received an error…which I then used in the next prompt.
There is an error “no viable alternative at input ‘union’
“Apologies for the confusion. The error “no viable alternative at input ‘union'” occurs because the union operation is not supported directly on empty dataframes in Spark.
To resolve this issue, you can create an empty dataframe with the desired schema and then append rows to it using unionByName. Here’s an updated version of the code that handles error logging correctly:”
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it.
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import current_timestamp
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Set the file path for the lakehouse tables
lakehouse_path = "lakehouse/default/Tables"
# Define the schema for error logs dataframe
error_logs_schema = "timestamp:timestamp, error_message:string"
# Create an empty dataframe to store error logs with defined schema
error_logs_df = spark.createDataFrame(spark.sparkContext.emptyRDD(), error_logs_schema)
try:
# Get a list of all table names in the lakehouse directory
table_names = spark.catalog.listTables()
table_names = [row.name for row in table_names]
# Loop through each table and process it
for table_name in table_names:
try:
# Read the table into a Spark dataframe
df = spark.read.table(table_name)
# Perform any necessary operations on the dataframe
except Exception as e:
# Log the error message and timestamp to the error logs dataframe
new_error_log = spark.createDataFrame([(current_timestamp(), str(e))], error_logs_schema)
error_logs_df = error_logs_df.unionByName(new_error_log)
# Save the error logs dataframe as a Delta table in the lakehouse
error_logs_table_name = "ErrorLogs"
error_logs_df.write.format("delta").mode("append").saveAsTable(error_logs_table_name)
except Exception as e:
print(f"Error retrieving table names: {str(e)}")
I could then run the code above without any issues. However, it’s incomplete so let’s just roll up everything into a single statement and see what we get.
For each table in the lakehouse beginning with “dim”, load into a dataframe, remove whitespace from all string columns, and save to a delta table prefixed with “cleansed_”. Add error handling to the loop which inserts errors into a Delta table
Here’s my “final” process, I couldn’t seem to keep the prompting “stateful” in that if I asked it to modify the code to add/change something it then removed parts of the original code that performed the action I initially wanted. So I simply typed out the full action I wanted it to perform, and it generated the code that ran successfully and did what I wanted it to do.
# ATTENTION: AI-generated code can include errors or operations you didn't intend. Review the code in this cell carefully before running it.
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import trim
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Set the file path for the lakehouse tables
lakehouse_path = "lakehouse/default/Tables"
# Get a list of all table names in the lakehouse directory starting with "dim"
table_names = [table.name for table in spark.catalog.listTables() if table.name.startswith("dim")]
# Create an empty dataframe to store error logs with defined schema
error_logs_schema = "timestamp:timestamp, error_message:string"
error_logs_df = spark.createDataFrame([], error_logs_schema)
# Loop through each table and process it with error handling
for table_name in table_names:
try:
# Read the table into a Spark dataframe
df = spark.read.table(table_name)
# Remove whitespace from string columns
for col in df.columns:
if df.schema[col].dataType == "string":
df = df.withColumn(col, trim(df[col]))
# Save the cleansed dataframe as a Delta table with prefix "cleansed_"
cleansed_table_name = f"cleansed_{table_name}"
df.write.format("delta").mode("overwrite").saveAsTable(cleansed_table_name)
except Exception as e:
# Log the error message and timestamp to the error logs dataframe
new_error_log = spark.createDataFrame([(current_timestamp(), str(e))], error_logs_schema)
error_logs_df = error_logs_df.union(new_error_log)
# Save the error logs dataframe as a Delta table in the lakehouse
error_logs_table_name = "ErrorLogs"
error_logs_df.write.format("delta").mode("append").saveAsTable(error_logs_table_name)
This worked fine and I could see the resulting table and contents of the table.
Conclusion
My first experience with Copilot in Fabric Data Engineering is positive, I definitely feel there is value here if you can ask the right questions. Yes, we’re definitely in the hypecycle here with Copilot, the real value will be determining if the effort to work with Copilot overrides learning how to do the thing you’re asking it to do. It looks like a great learning aid, as long as you can (try to) validate the results.
There is a problem though…how do I know if the code Copilot is generating is actually recommended and performant code? I’m trusting “the process” here… It’s promising, no doubt about it and I feel this will go some way to helping people get hands on and to launch/accelerate their learning journey.
References
- Overview of Copilot for Data Science and Data Engineering in Microsoft Fabric (preview) – Microsoft Fabric | Microsoft Learn
- Overview of Copilot in Fabric (preview) – Microsoft Fabric | Microsoft Learn
- Enable Copilot for Microsoft Fabric (preview) – Microsoft Fabric | Microsoft Learn
- Copilot in Fabric (preview) is available worldwide | Microsoft Fabric Blog | Microsoft Fabric
 Andy
Andy