

This blog forms part of the Mastering DP-500 exam series. A list of available blogs is here and is in association with Data Mozart.
Learning Focus
The learning focus for this blog concentrates on the following area in the Skills Measured document published by Microsoft. An overview of the exam and skills measures is here.
Query and transform data (20–25%)
Query data by using Azure Synapse Analytics
Please note that as this blog is focused on certification, the content is based on official Microsoft documentation. The References section contains all links used in this blog. This blog was originally published July 2021.
Partition Pruning
Serverless SQL Pools includes 2 SQL functions, filepath and filename, that can be used to return the folder path/name and file name from which a row of data originates from in the source Azure storage account. These 2 functions can also be used to filter on certain folders and files to reduce the amount of data processed and also to improve read performance. In this blog we’ll focus on the filepath function. We’ll use the term partition pruning during this blog post which means filtering on the source folders required to satisfy the SQL query. When no partition pruning is performed, all source folders are scanned which can be inefficient and increase data processed costs.
Microsoft Documentation
The official documentation is available here and covers basic examples when using filepath and filename.
Filepath Function Overview
The filepath function is used to return the folder path and folder name from the storage account that a particular row of data that is returned in a SQL query originated from. If the function is used without a parameter then the full folder path is returned when used in a SELECT statement. When used with a numeric parameter, it will return the value from the specific wildcard position in the BULK parameter.
Example Syntax
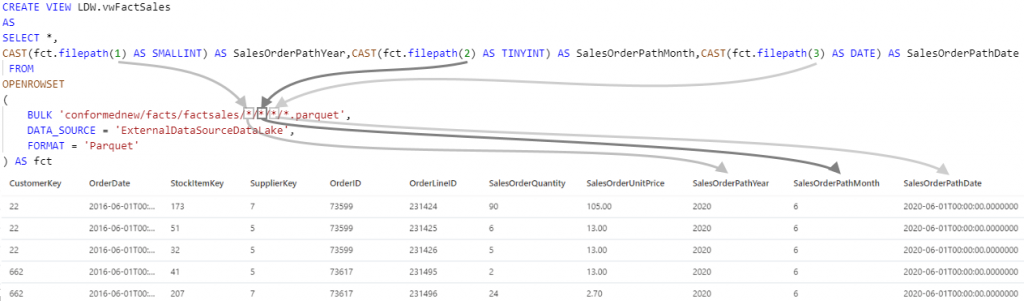
In the SQL code below, you can see that the filepath function is called with 3 different parameter values which represents a 3 level folder hierarchy. These values correspond to the * wildcard locations in the OPENROWSET BULK parameter. E.G fct.filepath(1) corresponds to the first * wildcard after conformed/facts/factsales/ and in this example will return the Year folder name.
SELECT *,
CAST(fct.filepath(1) AS SMALLINT) AS SalesOrderPathYear,
CAST(fct.filepath(2) AS TINYINT) AS SalesOrderPathMonth,
CAST(fct.filepath(3) AS DATE) AS SalesOrderPathDate
FROM
OPENROWSET
(
BULK 'conformed/facts/factsales/*/*/*/*.parquet',
DATA_SOURCE = 'ExternalDataSourceDataLake',
FORMAT = 'Parquet'
) AS fctCommon Use Cases
A common use case is to filter data stored in a date (and possibly time) folder structure such as /YYYY/MM/DD/ or /YYYY/MM/YYYY-MM-DD/. As new data is generated/sent/copied/moved to the storage account, a new folder is created for each specific time period. This strategy organises data into a maintainable folder structure.
Other Use Cases
However, source data does not need to be structured in a date folder structure and can be organised by a different structure such as by /department/business area/category etc. The filepath function will simply return the value of the folder structure when queried regardless of naming convention or structure.
Example View and Data Lake Folder Structure
We’ll now look at how we can use the filepath function in a SQL View to partition prune. We’ll look at what works in terms of using this in a WHERE clause and also when JOINing to other views like a Date Dimension. The data processed metrics for each query are available in a results table at the end of this blog post. Note that 10MB is the minimum data processed amount that Serverless SQL Pools support.
For this blog post the Azure Data Lake Gen2 storage account folder structure is set-up as /YYYY/MM/YYYY-MM-DD/ E.G. for each day of sales data there will be a folder such as /2020/06/2020-06-20/<parquet files>. For the SQL syntax examples below, we’ll be using 2 Views contained in a Serverless SQL pools database.
vwFactSales
CREATE VIEW LDW.vwFactSales
AS
SELECT *,
CAST(fct.filepath(1) AS SMALLINT) AS SalesOrderPathYear,
CAST(fct.filepath(2) AS TINYINT) AS SalesOrderPathMonth,
CAST(fct.filepath(3) AS DATE) AS SalesOrderPathDate
FROM
OPENROWSET
(
BULK 'conformed/facts/factsales/*/*/*/*.parquet',
DATA_SOURCE = 'ExternalDataSourceDataLake',
FORMAT = 'Parquet'
) AS fctExample Data

Source Folder Structure
The image below shows how the filepath() function is used to exposed the Year, Month, and Date source folders from the Data Lake in the view, how it maps to the wildcard locations in the BULK parameter, and how that maps to the values returned.
vwDimDate
CREATE VIEW LDW.vwDimDate
AS
SELECT * FROM
OPENROWSET
(
BULK 'conformed/dimensions/dimdate',
DATA_SOURCE = 'ExternalDataSourceDataLake',
FORMAT = 'Parquet'
) AS fctExample Data

SQL Syntax
Once we understand the source folder partition strategy, we can use filepath to filter on specific folders at specific levels in the folder hierarchy. However, there are some considerations and syntax that will work and not work, these are outlined below. It is important to consider syntax that will or will not work when live connecting external tools such as Business Intelligence software as SQL syntax is generated from these tools and pushed to Serverless SQL Pools.
Baseline data processed with no filtering/partition pruning is 217MB.
Select a Single Date
--Partition Prune (10MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
WHERE fct.SalesOrderPathDate= '2020-07-06'
--Partition Prune (10MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
INNER JOIN LDW.vwDimDate DD ON DD.[Date] = fct.SalesOrderPathDate
WHERE DD.[Date] = '2020-07-06'
In the queries above we can see that partition pruning is successful if the filepath function column SalesOrderPathDate in the Fact view is either filtered directly in the WHERE clause, or if it’s used to JOIN to the Date Dimension and then filtered using the Date field in the Date dimension view.
Select a Range of Dates
--Partition Prune (18MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
WHERE fct.SalesOrderPathDate BETWEEN '2020-07-06' AND '2020-07-19'
--No Partition Prune (217MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
INNER JOIN LDW.vwDimDate DD ON DD.[Date] = fct.SalesOrderPathDate
WHERE DD.[Date] BETWEEN '2020-07-06' AND '2020-07-19'However, we now see that if we join and then use the Date dimension view to filter based on a range using BETWEEN, it stops partition pruning. Using BETWEEN to filter on a date range directly on the Fact view does partition prune successfully.
Use YEAR and MONTH Function to Filter using WHERE
--Partition Prune (39MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
WHERE YEAR(fct.SalesOrderPathDate) = 2020 AND MONTH(fct.SalesOrderPathDate) = 7
--Partition Prune (39MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
INNER JOIN LDW.vwDimDate DD ON DD.[Month] = MONTH(fct.SalesOrderPathDate) AND DD.[Year] = YEAR(fct.SalesOrderPathDate)
WHERE DD.[Year] = 2020 AND DD.[Month] = 7We can use the SQL MONTH and YEAR functions to filter at a higher level. We see both queries above partition prune successfully including the Date Dimension view join, this is because single values are being passed into the Year and Month columns in the Date dimension view rather than a range (which does not partition prune).
Use YEAR and MONTH Function to Filter using IN
--Partition Prune (113MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
WHERE YEAR(fct.SalesOrderPathDate) = 2020 AND MONTH(fct.SalesOrderPathDate) IN (7,8,9)
--No Partition Prune (217MB)
SELECT SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
INNER JOIN LDW.vwDimDate DD ON DD.[Month] = MONTH(fct.SalesOrderPathDate) AND DD.[Year] = YEAR(fct.SalesOrderPathDate)
WHERE DD.[Year] = 2020 AND DD.[Month] IN (7,8,9)If we join the Fact view and Date Dimension view then filter using the Date dimension with a range, in this case IN, partition pruning does not work. However, using a range with IN directly on the Fact view partition prunes successfully.
Using Date Dimension Attributes to Group By
--Partition Prune (19MB)
SELECT DD.WeekDayName,
SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
INNER JOIN LDW.vwDimDate DD ON DD.[Date] = fct.SalesOrderPathDate
WHERE fct.SalesOrderPathDate BETWEEN '2020-07-06' AND '2020-07-19'
GROUP BY DD.WeekDayName
ORDER BY SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) DESC
--No Partition Prune (217MB)
SELECT DD.WeekDayName,
SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) AS SalesOrderQuantity
FROM LDW.vwFactSales AS fct
INNER JOIN LDW.vwDimDate DD ON DD.[Date] = fct.SalesOrderPathDate
WHERE DD.[Date] BETWEEN '2020-07-06' AND '2020-07-19'
GROUP BY DD.WeekDayName
ORDER BY SUM(CAST(fct.SalesOrderQuantity AS BIGINT)) DESCWe can use the Date Dimension attributes to GROUP BY in the query, but we are bound by the same limitations as the previous queries. We must either pass single values into the Date Dimension columns or filter on the Fact View SalesOrderPathDate column directly.
Data Processed Results
| Query | Data Processed | Partition Prune |
| Baseline Select with no filtering | 217MB | No |
| Select a Single Date with WHERE | 10MB | Yes |
| Select a Single Date with JOIN | 10MB | Yes |
| Select a Range of Dates with IN | 18MB | Yes |
| Select a Range of Dates with JOIN and IN | 217MB | No |
| Use YEAR and MONTH Function to Filter using WHERE | 39MB | Yes |
| Use YEAR and MONTH Function to Filter using WHERE and JOIN | 39MB | Yes |
| Use YEAR and MONTH Function to Filter using IN | 113MB | Yes |
| Use YEAR and MONTH Function to Filter using IN and JOIN | 217MB | No |
| Using Date Dimension Attributes to Group By | 19MB | Yes |
| Using Date Dimension Attributes to Group By and JOIN | 217MB | No |
Conclusion
As you can see when using the filepath function to partition prune there are caveats in terms of which SQL syntax will work and which will not if we wish to filter based on JOINing to another table such as a Date dimension. If we JOIN to another view and filter using a range, either IN or BETWEEN, partition pruning does not work. We can create the appropriate SQL to deal with these caveats, however we may have little to no control over a client tool that generates SQL such as Power BI.
 Andy
Andy
[…] Using Serverless SQL Pools to Querying Partitioned Sources in Azure Storage […]