

My PASS Data Community Summit 2021 recording is now available, please click here for the recording. I’ve re-watched the session and have some thoughts which are listed below in the What’s Changed section. The camera is positioned in the top-right, apologies for covering information – the slide deck can be found here.
Session Abstract
“In this session we’ll be creating a Logical Data Warehouse using Serverless SQL Pools. We’ll go through what a Logical Data Warehouse is and how Serverless SQL Pools supports this data warehousing method. We’ll then get hands on with connecting to data stored in Azure Data Lake Gen2 and how to load and model the data for analytical purposes.”
What’s Changed?
As this session was broadcast in October 2021, has anything changed in the 8 months between the original broadcast and the session being available to view on-demand? Well, after watching the session back I’ve pointed out several areas.
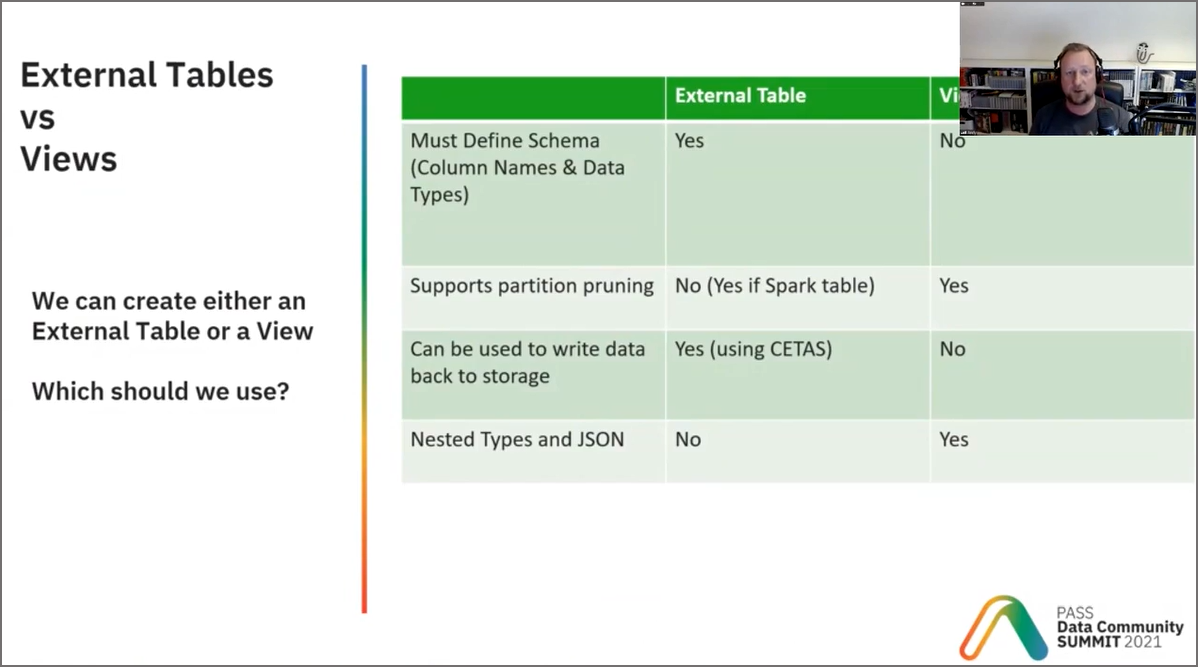
External Tables & Partition Pruning
At around 14 minutes there is a table showing a comparison between External Tables and Views, with an item stating that External Tables do not support partition pruning (processing only the required folders in the data lake). Using the Database Designer and Lake Databases, we are actually able to create External Tables with partition schemes that Serverless SQL Pools recognises.
Best Practices
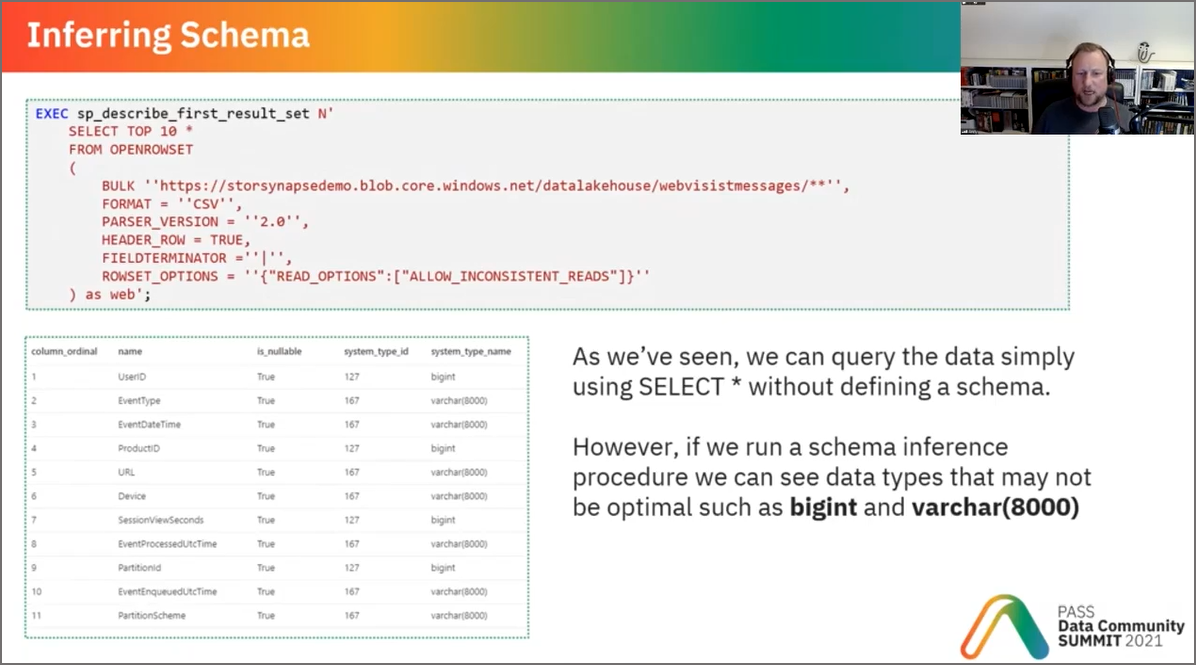
At around 20 minutes I talk about making sure that the correct data types and sizes are used to optimise performance, as of June 2022 this is not necessary as Serverless SQL Pools will optimise the data types automatically (see the update here). However, I would still recommend explicitly setting data types and sizes when querying data by using the WITH statement.
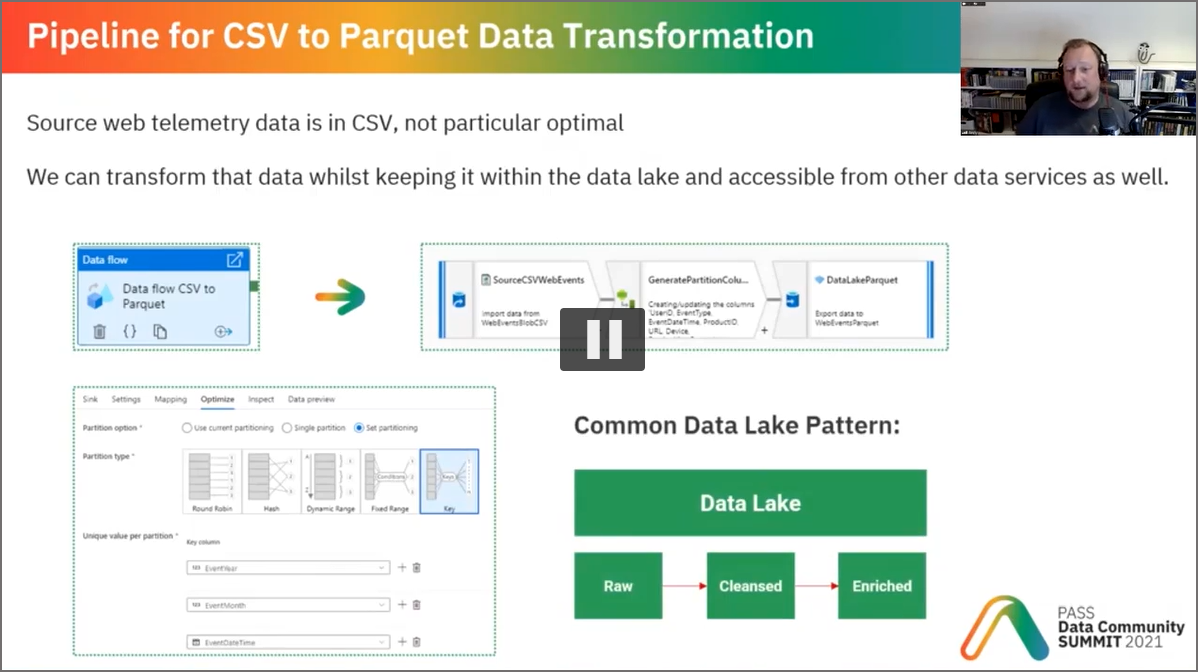
Mapping Data Flows
In the data transformation example at around 23 minutes, I would now swap out the Parquet sink and use a Delta sink. This would be beneficial in taking advantage of the benefits of Delta like schema evolution and transactional consistency.
Then there is the potential to replace Mapping Data Flows with Spark (Python/SQL) code (a conversation for another day…)
Power BI DirectQuery
Nothing has changed here but it’s worth calling out again, use DirectQuery in Power BI with Serverless SQL Pools with care (about 31 minutes in). Yes, you can technically do it but be mindful that each and every SQL query that Power BI issues will count towards data processed which is how you are being charged for the service. Lots of queries on large datasets could add up very quickly in terms of costs.

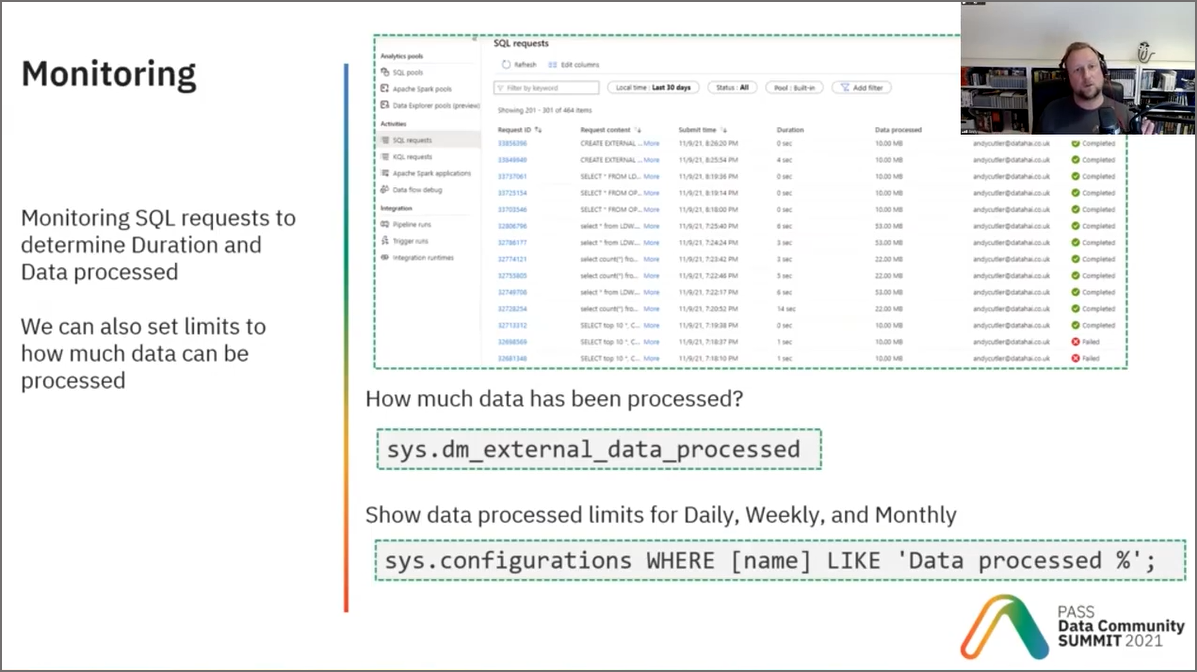
Data Processed Metrics
At around 36 minutes I talk through how to check data processed metrics, which is how you’re being charged for the Serverless SQL Pools service (currenty ~$5 per 1TB processed). Here is a SQL script you can use to query both how much data has been processed but also any daily/weekly/monthly limits that have been set on the Serverless SQL Pool itself. You can plug Power BI into this SQL script by creating a View and then creating a dashboard.
Security Access to Data Lake
In the demo at around 37 minutes I create a connection to the data lake and use User Identity which is Azure Active Directory pass-through authentication, my account needs access to both Serverless SQL Pools and also the underlying Azure Data Lake Gen2 account. An alternative to this would be using Managed Identity whereby the managed identity of the Synapse workspace is added with appropriate permissions to the Azure Data Lake Gen2 account. The reason for this is that Microsoft state there may be performance degradation when using pass-through authentication.
Pronunciation
I now say “Sin-apse” and not “Sign-apse” ?
 Andy
Andy
The current link no longer works – here’s an updated link to the archived recording:
https://passdatacommunitysummit.com/video-library/creating-a-logical-data-warehouse-using-azure-synapse-analytics-serverless-sql-pools/