SQLBits 2022 – The Dream Team: Synapse Analytics Serverless SQL Pools and Pipelines
I presented a 20 minute session at SQLBits 2022 in which I talked about how useful Synapse Pipelines can be when working with Serverless SQL Pools. The session included a slide deck and also a live demo, suffice to say that the delivery of the session was too quick with too much content to cover in the allotted time. My wish would be to present the session again, but with far less content to focus on a few core points.
In this blog I have added the slides with notes and thoughts about each slide. In a future blog (video), I’ll go through the technical demo. I’ll also have a separate “thank you SQLBits” blog over at my company’s site Datahai soon.
The slide deck is available to download here.

The session ran for 20 minutes on Thursday March 10th. At some point a video of the session will become available. I would suggest once the video becomes available, that you play the video at 0.5 speed…

For the agenda, we are looking at the basic services available in Synapse Analytics, then concentrating on Serverless SQL Pools and Pipelines. The Real-time and Batch solution is both a slide in the session and also forms the end-to-end technical demo.

I felt that as I was presenting about 2 of the Synapse services, Serverless SQL Pools & Pipelines, that I needed to provide a basic list of the other services available in Synapse Analytics. As Synapse has quite a few services, it’s not possible to go into any detail. Even a basic overview can take several minutes to run through. Should a session that covers a Synapse service also have an overview of the other services? I would not want to assume people had knowledge of the other services I was not covering.
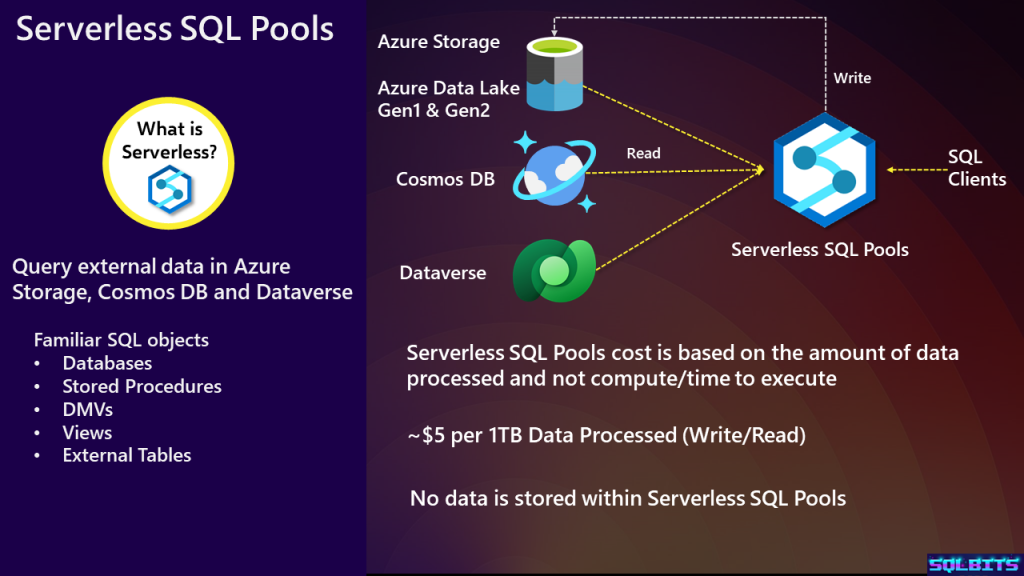
When working with Serverless SQL Pools, we are able to connect to the services listed in the slide and read data. We can also write data back to Azure Storage using CREATE EXTERNAL TABLE AS SELECT, which will create a folder and a set of Parquet files. There is very little control over the creation of these files including no way of partitioning, except to use dynamic SQL to construct the CETAS statement and iterate over data, which is not an ideal solution.
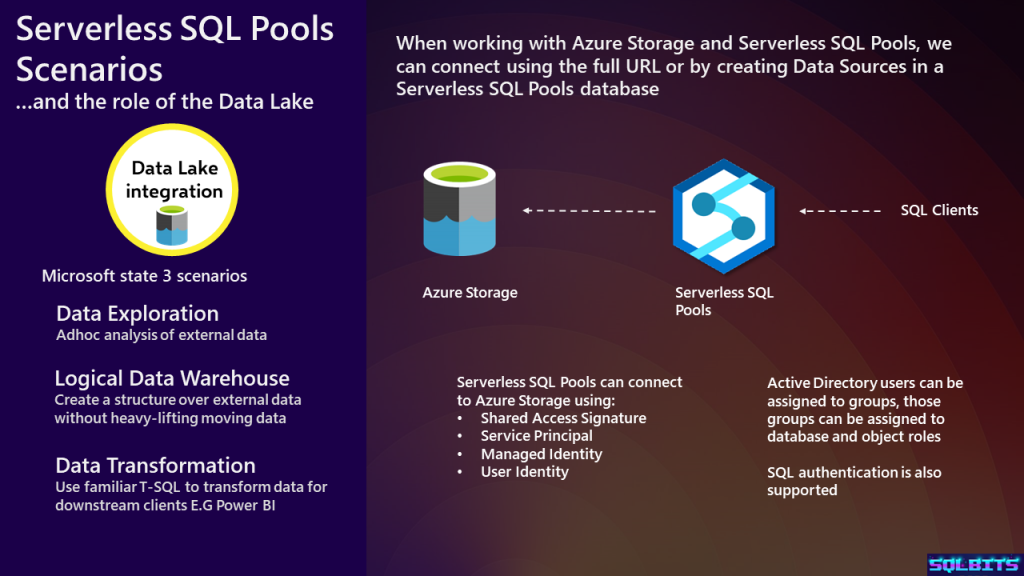
As we’re concentrating on using Serverless SQL Pools with Azure Storage, we have a list of the authentication methods available. Azure Data Lake Gen1 does not support Shared Access Signatures. The slide also contains a list of the 3 scenarios that Microsoft state Serverless SQL Pools can be used for, this list should have been the focus of a separate slide.

Why should we convert CSV and JSON files to Parquet? Well, Parquet offers a variety of benefits that Serverless SQL Pools can take advantage of. This includes data typing, by creating Parquet files with data types, Serverless SQL Pools can provision the required resources when executing a query. Parquet files support filtering, when executing a SQL query, only the required columns and rows are returned from the Parquet file, reducing data processed (and therefore cost) and improving query performance. In order the select columns and rows from a CSV file, Serverless must read the entire file.
In terms of orchestrating Serverless SQL View creation, the basic method here is to use Pipelines to pass in the name of a Data Lake folder to a Stored Procedure in a Serverless database. This Stored Procedure then dynamically generates a CREATE VIEW… statement over the source Data Lake folder, then executes the statement to create the view. This does save time when iterating over different folders, but has the disadvantage of having no control over data types within the view other than the data types Serverless infers.
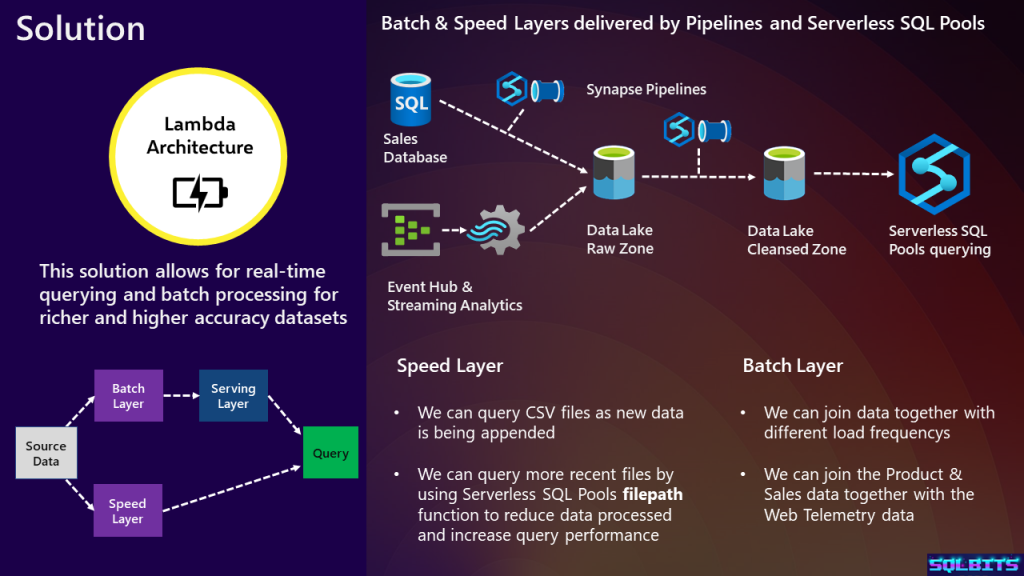
Here is a basic overview of Lambda architecture with a diagram of the batch and speed layers. The principle is that we can query basic data via the speed layer in real-time, whilst the batch layer with higher latency is more accurate, cleansed and enriched. There is also a basic architecture diagram of achieving the lambda architecture using Pipelines to move and transform data between Azure SQL Database and Data Lake folders. For the speed layer, Event Hubs and Streaming Analytics deliver data directly to a Data Lake Raw folder which Serverless can query directly (unfortunately not represented in the slide). The batch layer takes the raw data and copies/transforms into the Cleansed zone. In this slide we do not have a zone for the curated data, this is purely for simplicity in the technical demo.
As you can see, covering the above slides and also a technical demo proved far too much for a 20 minute session. In future, this will be available as a full-length session and a cut-down 20 and 10 minute session.







